目录
本文概览:在Kafka 0.11.0.0引入了EOS(exactly once semantics,精确一次处理语义)的特性,这个特性包括kafka幂等性和kafka事务两个属性。本小节对这个属性进行介绍。
1 生产者幂等性
1.1 引入
幂等性引入目的:
- 生产者重复生产消息。生产者进行retry会产生重试时,会重复产生消息。有了幂等性之后,在进行retry重试时,只会生成一个消息。
1.2 幂等性实现
1.2.1 PID 和 Sequence Number
为了实现Producer的幂等性,Kafka引入了Producer ID(即PID)和Sequence Number。
- PID。每个新的Producer在初始化的时候会被分配一个唯一的PID,这个PID对用户是不可见的。
- Sequence Numbler。(对于每个PID,该Producer发送数据的每个<Topic, Partition>都对应一个从0开始单调递增的Sequence Number。
Broker端在缓存中保存了这seq number,对于接收的每条消息,如果其序号比Broker缓存中序号大于1则接受它,否则将其丢弃。这样就可以实现了消息重复提交了。但是,只能保证单个Producer对于同一个<Topic, Partition>的Exactly Once语义。不能保证同一个Producer一个topic不同的partion幂等。
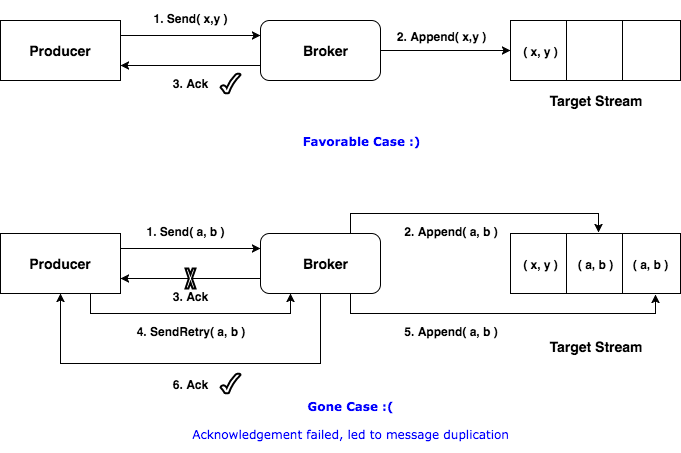
实现幂等之后
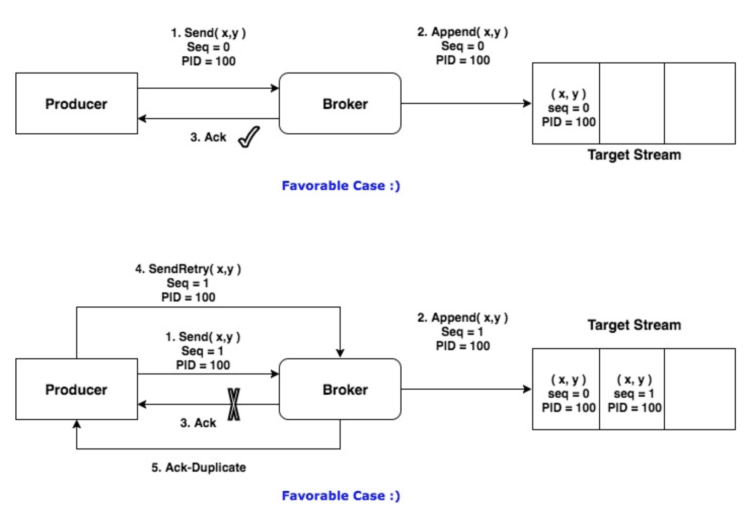
1.2.2 生成PID的流程
在执行创建事务时,如下
|
1 |
Producer<String, String> producer = new KafkaProducer<String, String>(props); |
会创建一个Sender,并启动线程,执行如下run方法,在maybeWaitForProducerId()中生成一个producerId,如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
==================================== 类名:Sender ==================================== void run(long now) { if (transactionManager != null) { try { ........ if (!transactionManager.isTransactional()) { // 为idempotent producer生成一个producer id maybeWaitForProducerId(); } else if (transactionManager.hasUnresolvedSequences() && !transactionManager.hasFatalError()) { ........ |
1.3 幂等性的应用实例
1、配置属性
需要设置:
- enable.idempotence,需要设置为ture,此时就会默认把acks设置为all,所以不需要再设置acks属性了。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
private Producer buildIdempotProducer(){ // create instance for properties to access producer configs Properties props = new Properties(); // bootstrap.servers是Kafka集群的IP地址。多个时,使用逗号隔开 props.put("bootstrap.servers", "localhost:9092"); props.put("enable.idempotence",true); //If the request fails, the producer can automatically retry, props.put("retries", 3); //Reduce the no of requests less than 0 props.put("linger.ms", 1); //The buffer.memory controls the total amount of memory available to the producer for buffering. props.put("buffer.memory", 33554432); // Kafka消息是以键值对的形式发送,需要设置key和value类型序列化器 props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); Producer<String, String> producer = new KafkaProducer<String, String>(props); return producer; } |
2、发送消息
跟一般生成者一样,如下
|
1 2 3 4 5 6 7 |
public void produceIdempotMessage(String topic, String message) { // 创建Producer Producer producer = buildIdempotProducer(); // 发送消息 producer.send(new ProducerRecord<String, String>(topic, message)); producer.flush(); } |
此时,因为我们并没有配置transaction.id属性,所以不能使用事务相关API,如下
|
1 |
producer.initTransactions(); |
否则会出现如下错误:
Exception in thread “main” java.lang.IllegalStateException: Transactional method invoked on a non-transactional producer.
at org.apache.kafka.clients.producer.internals.TransactionManager.ensureTransactional(TransactionManager.java:777)
at org.apache.kafka.clients.producer.internals.TransactionManager.initializeTransactions(TransactionManager.java:202)
at org.apache.kafka.clients.producer.KafkaProducer.initTransactions(KafkaProducer.java:544)
2 事务属性
2.1 事务属性理解
事务属性是2017年Kafka 0.11.0.0引入的新特性。类似于数据库事务,只是这里的数据源是Kafka,kafka事务属性是指一系列的生产者生产消息和消费者提交偏移量的操作在一个事务,或者说是是一个原子操作),同时成功或者失败。
注意:在理解消息的事务时,一直处于一个错误理解就是如下代码中,把操作db的业务逻辑跟操作消息当成是一个事务。其实这个是有问题的,操作DB数据库的数据源是DB,消息数据源是kfaka,这是完全不同两个数据,一种数据源(如mysql,kafka)对应一个事务,所以它们是两个独立的事务:kafka事务指kafka一系列 生产、消费消息等操作组成一个原子操作;db事务是指操作数据库的一系列增删改操作组成一个原子操作。
|
1 2 3 4 5 6 7 8 |
void kakfa_in_tranction(){ // 1.kafa的操作:读取消息或者生产消息 kafkaOperation(); // 2.db操作 dbOperation() } |
2.2 引入事务目的
在事务属性之前先引入了生产者幂等性,它的作用为:
- 生产者多次发送消息可以封装成一个原子操作,要么都成功,要么失败
- consumer-transform-producer模式下,因为消费者提交偏移量出现问题,导致在重复消费消息时,生产者重复生产消息。需要将这个模式下消费者提交偏移量操作和生成者一系列生成消息的操作封装成一个原子操作。
消费者提交偏移量导致重复消费消息的场景:消费者在消费消息完成提交便宜量o2之前挂掉了(假设它最近提交的偏移量是o1),此时执行再均衡时,其它消费者会重复消费消息(o1到o2之间的消息)。
2.3 事务操作的API
producer提供了initTransactions, beginTransaction, sendOffsets, commitTransaction, abortTransaction 五个事务方法。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
/** * 初始化事务。需要注意的有: * 1、前提 * 需要保证transation.id属性被配置。 * 2、这个方法执行逻辑是: * (1)Ensures any transactions initiated by previous instances of the producer with the same * transactional.id are completed. If the previous instance had failed with a transaction in * progress, it will be aborted. If the last transaction had begun completion, * but not yet finished, this method awaits its completion. * (2)Gets the internal producer id and epoch, used in all future transactional * messages issued by the producer. * */ public void initTransactions(); /** * 开启事务 */ public void beginTransaction() throws ProducerFencedException ; /** * 为消费者提供的在事务内提交偏移量的操作 */ public void sendOffsetsToTransaction(Map<TopicPartition, OffsetAndMetadata> offsets, String consumerGroupId) throws ProducerFencedException ; /** * 提交事务 */ public void commitTransaction() throws ProducerFencedException; /** * 放弃事务,类似回滚事务的操作 */ public void abortTransaction() throws ProducerFencedException ; |
3 事务属性的应用实例
在一个原子操作中,根据包含的操作类型,可以分为三种情况,前两种情况是事务引入的场景,最后一种情况没有使用价值。
只有Producer生产消息;
消费消息和生产消息并存,这个是事务场景中最常用的情况,就是我们常说的“consume-transform-produce ”模式
只有consumer消费消息,这种操作其实没有什么意义,跟使用手动提交效果一样,而且也不是事务属性引入的目的,所以一般不会使用这种情况
3.1 相关属性配置
使用kafka的事务api时的一些注意事项:
- 需要消费者的自动模式设置为false,并且不能子再手动的进行执行consumer#commitSync或者consumer#commitAsyc
- 生产者配置transaction.id属性
- 生产者不需要再配置enable.idempotence,因为如果配置了transaction.id,则此时enable.idempotence会被设置为true
- 消费者需要配置Isolation.level。在consume-trnasform-produce模式下使用事务时,必须设置为READ_COMMITTED。
3.2 只有写
创建一个事务,在这个事务操作中,只有生成消息操作。代码如下:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
/** * 在一个事务只有生产消息操作 */ public void onlyProduceInTransaction() { Producer producer = buildProducer(); // 1.初始化事务 producer.initTransactions(); // 2.开启事务 producer.beginTransaction(); try { // 3.kafka写操作集合 // 3.1 do业务逻辑 // 3.2 发送消息 producer.send(new ProducerRecord<String, String>("test", "transaction-data-1")); producer.send(new ProducerRecord<String, String>("test", "transaction-data-2")); // 3.3 do其他业务逻辑,还可以发送其他topic的消息。 // 4.事务提交 producer.commitTransaction(); } catch (Exception e) { // 5.放弃事务 producer.abortTransaction(); } } |
创建生成者,代码如下,需要:
- 配置transactional.id属性
- 配置enable.idempotence属性
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 |
/** * 需要: * 1、设置transactional.id * 2、设置enable.idempotence * @return */ private Producer buildProducer() { // create instance for properties to access producer configs Properties props = new Properties(); // bootstrap.servers是Kafka集群的IP地址。多个时,使用逗号隔开 props.put("bootstrap.servers", "localhost:9092"); // 设置事务id props.put("transactional.id", "first-transactional"); // 设置幂等性 props.put("enable.idempotence",true); //Set acknowledgements for producer requests. props.put("acks", "all"); //If the request fails, the producer can automatically retry, props.put("retries", 1); //Specify buffer size in config,这里不进行设置这个属性,如果设置了,还需要执行producer.flush()来把缓存中消息发送出去 //props.put("batch.size", 16384); //Reduce the no of requests less than 0 props.put("linger.ms", 1); //The buffer.memory controls the total amount of memory available to the producer for buffering. props.put("buffer.memory", 33554432); // Kafka消息是以键值对的形式发送,需要设置key和value类型序列化器 props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer"); props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer"); Producer<String, String> producer = new KafkaProducer<String, String>(props); return producer; } |
3.3 消费-生产并存(consume-transform-produce)
在一个事务中,既有生产消息操作又有消费消息操作,即常说的Consume-tansform-produce模式。如下实例代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
/** * 在一个事务内,即有生产消息又有消费消息 */ public void consumeTransferProduce() { // 1.构建上产者 Producer producer = buildProducer(); // 2.初始化事务(生成productId),对于一个生产者,只能执行一次初始化事务操作 producer.initTransactions(); // 3.构建消费者和订阅主题 Consumer consumer = buildConsumer(); consumer.subscribe(Arrays.asList("test")); while (true) { // 4.开启事务 producer.beginTransaction(); // 5.1 接受消息 ConsumerRecords<String, String> records = consumer.poll(500); try { // 5.2 do业务逻辑; System.out.println("customer Message---"); Map<TopicPartition, OffsetAndMetadata> commits = Maps.newHashMap(); for (ConsumerRecord<String, String> record : records) { // 5.2.1 读取消息,并处理消息。print the offset,key and value for the consumer records. System.out.printf("offset = %d, key = %s, value = %s\n", record.offset(), record.key(), record.value()); // 5.2.2 记录提交的偏移量 commits.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset())); // 6.生产新的消息。比如外卖订单状态的消息,如果订单成功,则需要发送跟商家结转消息或者派送员的提成消息 producer.send(new ProducerRecord<String, String>("test", "data2")); } // 7.提交偏移量 producer.sendOffsetsToTransaction(commits, "group0323"); // 8.事务提交 producer.commitTransaction(); } catch (Exception e) { // 7.放弃事务 producer.abortTransaction(); } } } |
创建消费者代码,需要:
- 将配置中的自动提交属性(auto.commit)进行关闭
- 而且在代码里面也不能使用手动提交commitSync( )或者commitAsync( )
- 设置isolation.level
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 |
/** * 需要: * 1、关闭自动提交 enable.auto.commit * 2、isolation.level为 * @return */ public Consumer buildConsumer() { Properties props = new Properties(); // bootstrap.servers是Kafka集群的IP地址。多个时,使用逗号隔开 props.put("bootstrap.servers", "localhost:9092"); // 消费者群组 props.put("group.id", "group0323"); // 设置隔离级别 props.put("isolation.level","read_committed"); // 关闭自动提交 props.put("enable.auto.commit", "false"); props.put("session.timeout.ms", "30000"); props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer"); KafkaConsumer<String, String> consumer = new KafkaConsumer <String, String>(props); return consumer; } |
3.4 只有读
创建一个事务,在这个事务操作中,只有生成消息操作,如下代码。这种操作其实没有什么意义,跟使用手动提交效果一样,无法保证消费消息操作和提交偏移量操作在一个事务。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 |
** * 在一个事务只有消息操作 */ public void onlyConsumeInTransaction() { Producer producer = buildProducer(); // 1.初始化事务 producer.initTransactions(); // 2.开启事务 producer.beginTransaction(); // 3.kafka读消息的操作集合 Consumer consumer = buildConsumer(); while (true) { // 3.1 接受消息 ConsumerRecords<String, String> records = consumer.poll(500); try { // 3.2 do业务逻辑; System.out.println("customer Message---"); Map<TopicPartition, OffsetAndMetadata> commits = Maps.newHashMap(); for (ConsumerRecord<String, String> record : records) { // 3.2.1 处理消息 print the offset,key and value for the consumer records. System.out.printf("offset = %d, key = %s, value = %s\n", record.offset(), record.key(), record.value()); // 3.2.2 记录提交偏移量 commits.put(new TopicPartition(record.topic(), record.partition()), new OffsetAndMetadata(record.offset())); } // 4.提交偏移量 producer.sendOffsetsToTransaction(commits, "group0323"); // 5.事务提交 producer.commitTransaction(); } catch (Exception e) { // 6.放弃事务 producer.abortTransaction(); } } } |
4 生产者事务的实现
4.1 相关配置
4.1.1 Broker configs
| ransactional.id.timeout.ms | The maximum amount of time in ms that the transaction coordinator will wait before proactively expire a producer TransactionalId without receiving any transaction status updates from it.
Default is 604800000 (7 days). This allows periodic weekly producer jobs to maintain their ids. |
| max.transaction.timeout.ms | The maximum allowed timeout for transactions. If a client’s requested transaction time exceed this, then the broker will return a InvalidTransactionTimeout error in InitPidRequest. This prevents a client from too large of a timeout, which can stall consumers reading from topics included in the transaction.
Default is 900000 (15 min). This is a conservative upper bound on the period of time a transaction of messages will need to be sent. |
| transaction.state.log.replication.factor | The number of replicas for the transaction state topic.
Default: 3 |
| transaction.state.log.num.partitions | The number of partitions for the transaction state topic.
Default: 50 |
| transaction.state.log.min.isr | The minimum number of insync replicas the each partition of the transaction state topic needs to have to be considered online.
Default: 2 |
| transaction.state.log.segment.bytes | The segment size for the transaction state topic.
Default: 104857600 bytes. |
4.1.2 Producer configs
|
enable.idempotence
|
Whether or not idempotence is enabled (false by default). If disabled, the producer will not set the PID field in produce requests and the current producer delivery semantics will be in effect. Note that idempotence must be enabled in order to use transactions.
When idempotence is enabled, we enforce that acks=all, retries > 1, and max.inflight.requests.per.connection=1. Without these values for these configurations, we cannot guarantee idempotence. If these settings are not explicitly overidden by the application, the producer will set acks=all, retries=Integer.MAX_VALUE, and max.inflight.requests.per.connection=1 when idempotence is enabled. |
| transaction.timeout.ms | The maximum amount of time in ms that the transaction coordinator will wait for a transaction status update from the producer before proactively aborting the ongoing transaction.
This config value will be sent to the transaction coordinator along with the InitPidRequest. If this value is larger than the max.transaction.timeout.ms setting in the broker, the request will fail with a Default is 60000. This makes a transaction to not block downstream consumption more than a minute, which is generally allowable in real-time apps. |
| transactional.id | The TransactionalId to use for transactional delivery. This enables reliability semantics which span multiple producer sessions since it allows the client to guarantee that transactions using the same TransactionalId have been completed prior to starting any new transactions. If no TransactionalId is provided, then the producer is limited to idempotent delivery.
如果配置了transactional.id属性,则 |
4.1.3 Consumer configs
- read_uncommitted,类似没有设置事务属性的consumer,即就是我们平常使用的consumer,只要消息写入到文件中就可以进行读取。
| isolation.level | Here are the possible values (default is read_uncommitted):
read_uncommitted: consume both committed and uncommitted messages in offset ordering. read_committed: only consume non-transactional messages or committed transactional messages in offset order. In order to maintain offset ordering, this setting means that we will have to buffer messages in the consumer until we see all messages in a given transaction. |
4.2 幂等性和事务性的关系
4.2.1 两者关系
事务属性实现前提是幂等性,即在配置事务属性transaction id时,必须还得配置幂等性;但是幂等性是可以独立使用的,不需要依赖事务属性。
- 幂等性引入了Porducer ID
- 事务属性引入了Transaction Id属性。、
设置
- enable.idempotence = true,transactional.id不设置:只支持幂等性。
- enable.idempotence = true,transactional.id设置:支持事务属性和幂等性
- enable.idempotence = false,transactional.id不设置:没有事务属性和幂等性的kafka
- enable.idempotence = false,transactional.id设置:无法获取到PID,此时会报错
4.2.2 tranaction id 、productid 和 epoch
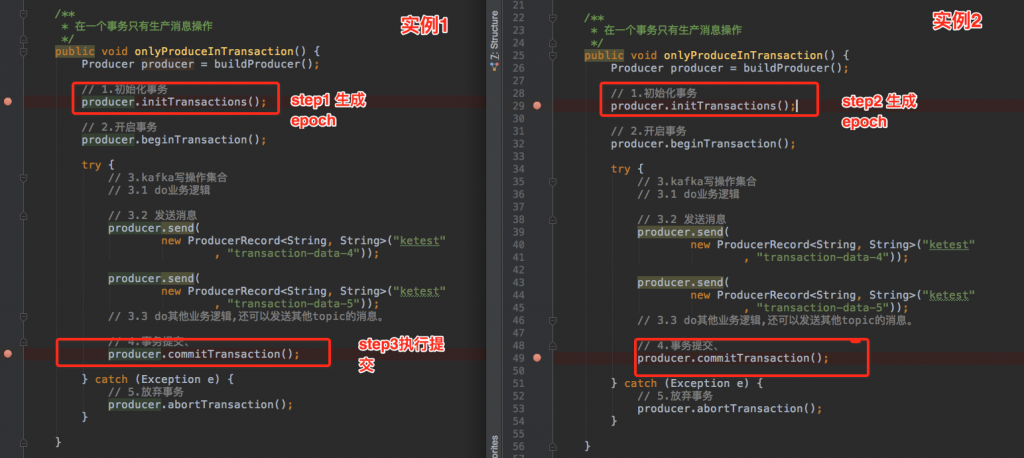
一个app有一个tid,同一个应用的不同实例PID是一样的,只是epoch的值不同。如:
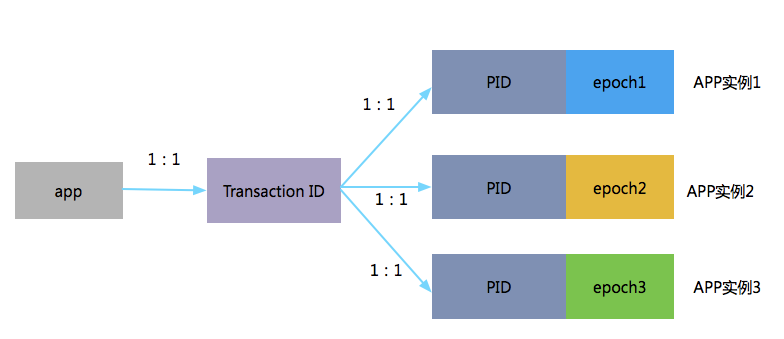
同一份代码运行两个实例,分步执行如下:在实例1没有进行提交事务前,开始执行实例2的初始化事务
step1 实例1-初始化事务。的打印出对应productId和epoch,信息如下:
[2018-04-21 20:56:23,106] INFO [TransactionCoordinator id=0] Initialized transactionalId first-transactional with producerId 8000 and producer epoch 123 on partition __transaction_state-12 (kafka.coordinator.transaction.TransactionCoordinator)
step2 实例1-发送消息。
step3 实例2-初始化事务。初始化事务时的打印出对应productId和epoch,信息如下:
18-04-21 20:56:48,373] INFO [TransactionCoordinator id=0] Initialized transactionalId first-transactional with producerId 8000 and producer epoch 124 on partition __transaction_state-12 (kafka.coordinator.transaction.TransactionCoordinator)
step4 实例1-提交事务,此时报错
org.apache.kafka.common.errors.ProducerFencedException: Producer attempted an operation with an old epoch. Either there is a newer producer with the same transactionalId, or the producer’s transaction has been expired by the broker.
step5 实例2-提交事务
为了避免这种错误,同一个事务ID,只有保证如下顺序epch小producer执行init-transaction和committransaction,然后epoch较大的procuder才能开始执行init-transaction和commit-transaction,如下顺序:
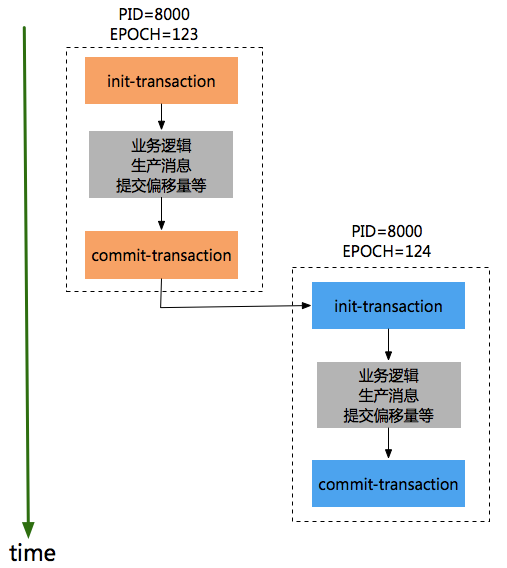
有了transactionId后,Kafka可保证:
- 跨Session的数据幂等发送。当具有相同Transaction ID的新的Producer实例被创建且工作时,旧的且拥有相同Transaction ID的Producer将不再工作【上面的实例可以验证】。kafka保证了关联同一个事务的所有producer(一个应用有多个实例)必须按照顺序初始化事务、和提交事务,否则就会有问题,这保证了同一事务ID中消息是有序的(不同实例得按顺序创建事务和提交事务)。
4.3 事务最佳实践-单实例的事务性
通过上面实例中可以看到kafka是跨Session的数据幂等发送,即如果应用部署多个实例时常会遇到上面的问题“org.apache.kafka.common.errors.ProducerFencedException: Producer attempted an operation with an old epoch. Either there is a newer producer with the same transactionalId, or the producer’s transaction has been expired by the broker.”,必须保证这些实例生成者的提交事务顺序和创建顺序保持一致才可以,否则就无法成功。其实,在实践中,我们更多的是如何实现对应用单实例的事务性。可以通过spring-kafaka实现思路来学习,即每次创建生成者都设置一个不同的transactionId的值,如下代码:
在spring-kafka中,对于一个线程创建一个producer,事务提交之后,还会关闭这个producer并清除,后续同一个线程或者新的线程重新执行事务时,此时就会重新创建producer。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 |
==================================== 类名:ProducerFactoryUtils ==================================== /** * Obtain a Producer that is synchronized with the current transaction, if any. * @param producerFactory the ConnectionFactory to obtain a Channel for * @param <K> the key type. * @param <V> the value type. * @return the resource holder. */ public static <K, V> KafkaResourceHolder<K, V> getTransactionalResourceHolder( final ProducerFactory<K, V> producerFactory) { Assert.notNull(producerFactory, "ProducerFactory must not be null"); // 1.对于每一个线程会生成一个唯一key,然后根据key去查找resourceHolder @SuppressWarnings("unchecked") KafkaResourceHolder<K, V> resourceHolder = (KafkaResourceHolder<K, V>) TransactionSynchronizationManager .getResource(producerFactory); if (resourceHolder == null) { // 2.创建一个消费者 Producer<K, V> producer = producerFactory.createProducer(); // 3.开启事务 producer.beginTransaction(); resourceHolder = new KafkaResourceHolder<K, V>(producer); bindResourceToTransaction(resourceHolder, producerFactory); } return resourceHolder; } |
创建消费者代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
==================================== 类名:DefaultKafkaProducerFactory ==================================== protected Producer<K, V> createTransactionalProducer() { Producer<K, V> producer = this.cache.poll(); if (producer == null) { Map<String, Object> configs = new HashMap<>(this.configs); // 对于每一次生成producer时,都设置一个不同的transactionId configs.put(ProducerConfig.TRANSACTIONAL_ID_CONFIG, this.transactionIdPrefix + this.transactionIdSuffix.getAndIncrement()); producer = new KafkaProducer<K, V>(configs, this.keySerializer, this.valueSerializer); // 1.初始化话事务。 producer.initTransactions(); return new CloseSafeProducer<K, V>(producer, this.cache); } else { return producer; } } |
4.4 Consume-transform-Produce 的流程
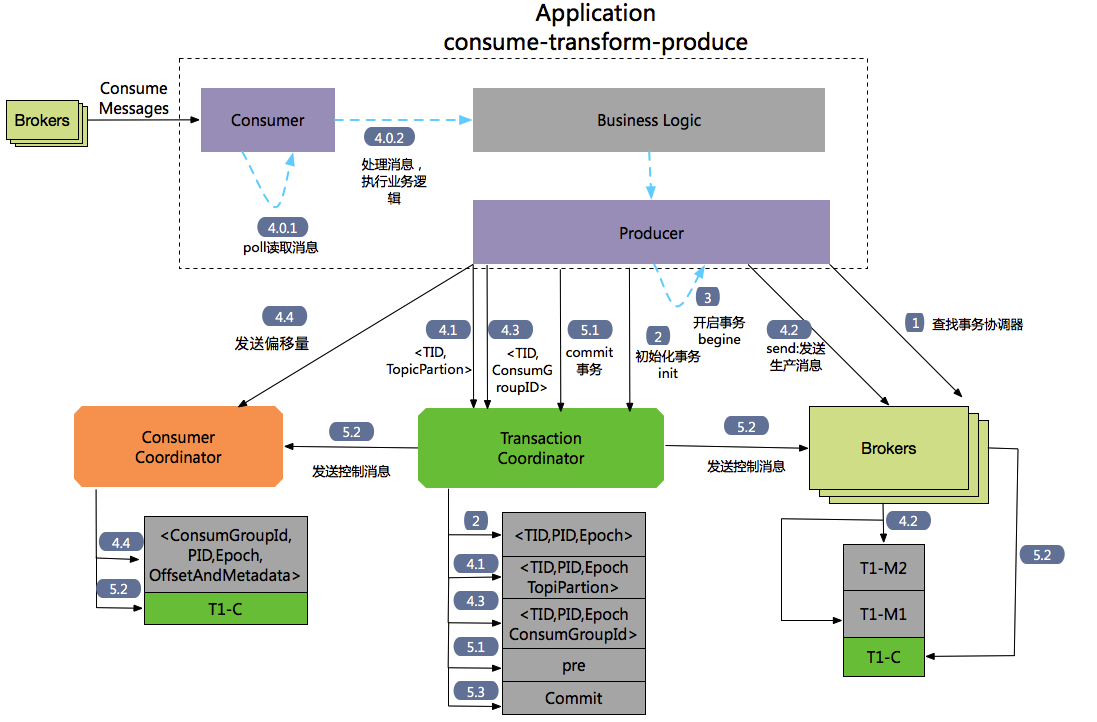
流程1 :查找Tranaction Corordinator。
Producer向任意一个brokers发送 FindCoordinatorRequest请求来获取Transaction Coordinator的地址。
流程2:初始化事务 initTransaction
Producer发送InitpidRequest给事务协调器,获取一个Pid。InitpidRequest的处理过程是同步阻塞的,一旦该调用正确返回,Producer就可以开始新的事务。TranactionalId通过InitpidRequest发送给Tranciton Corordinator,然后在Tranaciton Log中记录这<TranacionalId,pid>的映射关系。除了返回PID之外,还具有如下功能:
- 对PID对应的epoch进行递增,这样可以保证同一个app的不同实例对应的PID是一样的,但是epoch是不同的。
- 回滚之前的Producer未完成的事务(如果有)。
流程3: 开始事务beginTransaction
执行Producer的beginTransacion(),它的作用是Producer在本地记录下这个transaction的状态为开始状态。
注意:这个操作并没有通知Transaction Coordinator。
流程4: Consume-transform-produce loop
流程4.0: 通过Consumtor消费消息,处理业务逻辑
流程4.1: producer向TransactionCordinantro发送AddPartitionsToTxnRequest
在producer执行send操作时,如果是第一次给<topic,partion>发送数据,此时会向Trasaction Corrdinator发送一个AddPartitionsToTxnRequest请求,Transaction Corrdinator会在transaction log中记录下tranasactionId和<topic,partion>一个映射关系,并将状态改为begin。AddPartionsToTxnRequest的数据结构如下:
|
1 2 3 4 5 6 |
AddPartitionsToTxnRequest => TransactionalId PID Epoch [Topic [Partition]] TransactionalId => string PID => int64 Epoch => int16 Topic => string Partition => int32 |
流程4.2: producer#send发送 ProduceRequst
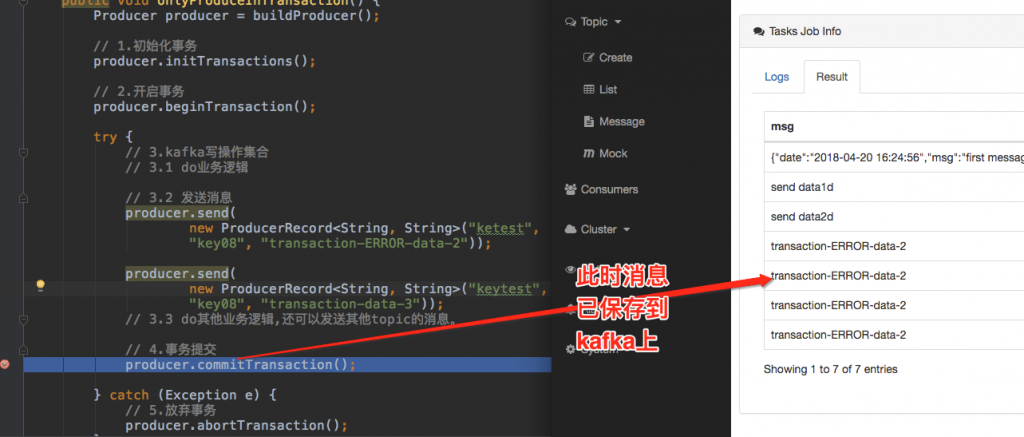
生产者发送数据,虽然没有还没有执行commit或者absrot,但是此时消息已经保存到kafka上,可以参考如下图断点位置处,此时已经可以查看到消息了,而且即使后面执行abort,消息也不会删除,只是更改状态字段标识消息为abort状态。
流程4.3: AddOffsetCommitsToTxnRequest
Producer通过KafkaProducer.sendOffsetsToTransaction 向事务协调器器发送一个AddOffesetCommitsToTxnRequests:
|
1 2 3 4 5 |
AddOffsetsToTxnRequest => TransactionalId PID Epoch ConsumerGroupID TransactionalId => string PID => int64 Epoch => int16 ConsumerGroupID => string |
在执行事务提交时,可以根据ConsumerGroupID来推断_customer_offsets主题中相应的TopicPartions信息。这样在
流程4.4: TxnOffsetCommitRequest
Producer通过KafkaProducer.sendOffsetsToTransaction还会向消费者协调器Cosumer Corrdinator发送一个TxnOffsetCommitRequest,在主题_consumer_offsets中保存消费者的偏移量信息。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
TxnOffsetCommitRequest => ConsumerGroupID PID Epoch RetentionTime OffsetAndMetadata ConsumerGroupID => string PID => int64 Epoch => int32 RetentionTime => int64 OffsetAndMetadata => [TopicName [Partition Offset Metadata]] TopicName => string Partition => int32 Offset => int64 Metadata => string |
流程5: 事务提交和事务终结(放弃事务)
通过生产者的commitTransaction或abortTransaction方法来提交事务和终结事务,这两个操作都会发送一个EndTxnRequest给Transaction Coordinator。
流程5.1:EndTxnRequest。Producer发送一个EndTxnRequest给Transaction Coordinator,然后执行如下操作:
- Transaction Coordinator会把PREPARE_COMMIT or PREPARE_ABORT 消息写入到transaction log中记录
- 执行流程5.2
- 执行流程5.3
流程5.2:WriteTxnMarkerRequest
|
1 2 3 4 5 6 7 |
WriteTxnMarkersRequest => [CoorinadorEpoch PID Epoch Marker [Topic [Partition]]] CoordinatorEpoch => int32 PID => int64 Epoch => int16 Marker => boolean (false(0) means ABORT, true(1) means COMMIT) Topic => string Partition => int32 |
- 对于Producer生产的消息。Tranaction Coordinator会发送WriteTxnMarkerRequest给当前事务涉及到每个<topic,partion>的leader,leader收到请求后,会写入一个COMMIT(PID) 或者 ABORT(PID)的控制信息到data log中
- 对于消费者偏移量信息,如果在这个事务里面包含_consumer-offsets主题。Tranaction Coordinator会发送WriteTxnMarkerRequest给Transaction Coordinartor,Transaction Coordinartor收到请求后,会写入一个COMMIT(PID) 或者 ABORT(PID)的控制信息到 data log中。
流程5.3:Transaction Coordinator会将最终的COMPLETE_COMMIT或COMPLETE_ABORT消息写入Transaction Log中以标明该事务结束。
- 只会保留这个事务对应的PID和timstamp。然后把当前事务其他相关消息删除掉,包括PID和tranactionId的映射关系。
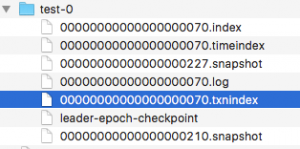
4.4.1 文件类型和查看命令
kafka文件主要包括broker的data(主题:test)、事务协调器对应的transaction_log(主题:__tranaction_state)、偏移量信息(主题:_consumer_offsets)三种类型。如下图
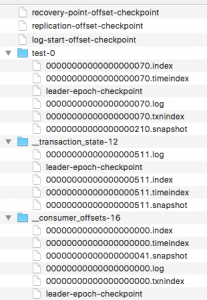
这三种文件类型其实都是topic的分区,所以对于每一个目录都包含*.log、*.index、*.timeindex、*.txnindex文件(仅这个文件是为了实现事务属性引入的)。segment和segmengt对应index、timeindex、txnindex文件命名中序号表示的是第几个消息。如下图中,00000000000000368769.index和00000000000000568769.log中“368969”就是表示文件中存储的第一个消息是468969个消息。
对于索引文案包含两部分:
- baseOffset:索引对应segment文件中的第几条message。
- position:在segment中的绝对位置。
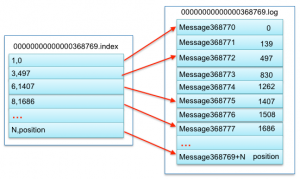
查看文件内容:
bin/kafka-run-class.sh kafka.tools.DumpLogSegments –files /Users/wuzhonghu/data/kafka-logs/firtstopic-0/00000000000000000002.log –print-data-log
4.4.2 ControlMessage和Transaction markers
Trasaction markers就是kafka为了实现事务定义的Controll Message。这个消息和数据消息都存放在log中,在Consumer读取事务消息时有用,可以参考下面章节-4.5.1 老版本-读取事务消息顺序。
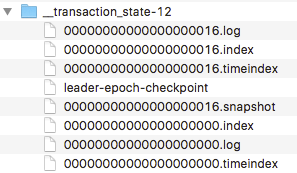
4.4.3 Transaction Coordinator 和 Transaction Log
Transaction Log如下放置在“_tranaction_state”主题下面,默认是50个分区,每一个分区中文件格式和broker存储消息是一样的,都有log/index/timeindex文件,如下:
4.5 消费读取事务消息(READ_COMMITED)
Consumer为了实现事务,新增了一个isolation.level配置,有两个值如下,
- READ_UNCOMMITTED,类似于没有事务属性的消费者。
- READ_COMMITED,只获取执行了事务提交的消息。
在本小节中我们主要讲READ_COMMITED模式下读取消息的流程的两种版本的演化
4.5.1 老版本-读取事务消息顺序
如下图中,按顺序保存到broker中消息有:事务1消息T1-M1、对于事务2的消息有T2-M1、事务1消息T1-M2、非事务消息M1,最终到达client端的循序是M1-> T2-M1 -> T1-M1 -> T1-M2。
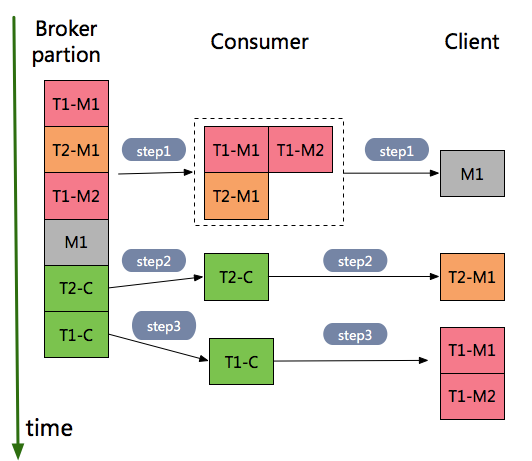
具体步骤如下:
- step1 Consumer接受到事务消息T1-M1、T2-M2、T1-M2和非事务消息M1,因为没有收到事务T1和T2的控制消息,所以此时把事务相关消息T1-M1、T2-M2、T1-M2 保存到内存,然后只把非事务消息M1返回给client。
- step2 Consumer接受到事务2的控制消息T2-C,此时就把事务消息T2-M1发送给Clinet。
- step3 C onsumer接受到事务1的控制消息T1-C,此时就把事务消息T1-M1和T1-M2发送给Client
4.5.2 新版本-读取事务消息顺序
第一种方式,需要在consumer客户端缓存消息,当存在耗时比较长的事务时,占用客户端大量的内存资源。为了解决这个问题,通过LSO和Abort Index 文件来解决这个问题,参考:
https://docs.google.com/document/d/1Rlqizmk7QCDe8qAnVW5e5X8rGvn6m2DCR3JR2yqwVjc/edit
(1) LSO,Last stable offset。Broker在缓存中维护了所有处于运行状态的事务对应的initial offsets,LSO的值就是这些offsets中最小值-1。这样在LSO之前数据都是已经commit或者abort的数据,只有这些数据才对Consumer可见,即consumer读取数据只能读取到LSO的位置。
- LSO并没有持久化某一个位置,而是实时计算出来的,并保存在缓存中。
(2)Absort Index文件
Conusmer发送FetchRequest中,新增了Isolation字段,表示是那种模式
|
1 2 3 4 5 6 7 8 9 10 |
ReplicaId MaxWaitTime MinBytes [TopicName [Partition FetchOffset MaxBytes]] ReplicaId => int32 MaxWaitTime => int32 MinBytes => int32 TopicName => string Partition => int32 FetchOffset => int64 MaxBytes => int32 Isolation => READ_COMMITTED | READ_UNCOMMITTED |
返回数据类型为FetchResponse的格式为:
ThrottleTime [TopicName [Partition ErrorCode HighwaterMarkOffset AbortedTransactions MessageSetSize MessageSet]]
对应各个给字段类型为
|
1 2 3 4 5 6 7 8 9 |
ThrottleTime => int32 TopicName => string Partition => int32 ErrorCode => int16 HighwaterMarkOffset => int64 AbortedTransactions => [PID FirstOffset] PID => int64 FirstOffset => int64 MessageSetSize => int32 |
- 设置成 READ_UNCOMMITTED 模式时, the AbortedTransactions array is null.
- 设置为READ_COMMITTED时,the Last Stable Offset(LSO),当事务提交之后,LSO向前移动offset
数据如下:
- 存放数据的log

- 存放Absort Index的内容如下:
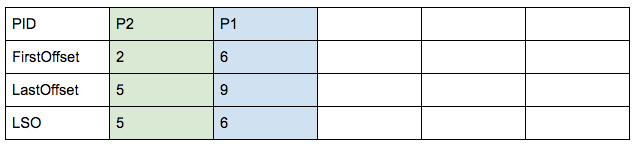
执行读取数据流程如下:
step1: 假设consumer读取数据的fetched offsets的区间是0到4。
- 首先,broker读取data log中数据

- 然后,broker依次读取abort index的内容,发现LSO大于等于 4 就停止。如上可以获取到P2对应的offset从2到5的消息都是被丢弃的:
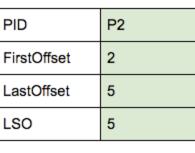
- 最后,broker将上面data log和abort index中满足条件的数据返回给consumer。
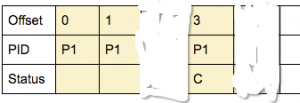
step2 :在consumer端根据absrot index中返回的内容,过滤丢弃的消息,最终给用户消息为
4.5.3 Absorted Transaction Index
在broker中数据中新增一个索引文件,保存aborted tranasation对应的offsets,只有事务执行abort时,才会往这个文件新增一个记录,初始这个文件是不存在的,只有第一条abort 时,才会创建这个文件。
这个索引文件结构的每一行结构是TransactionEntry:
|
1 2 3 4 5 |
Version => int16 PID => int64 FirstOffset => int64 LastOffset => int64 LastStableOffset => int64 |
当broker接受到控制消息(producer执行commitTransaction()或者abortTransaction())时, 执行如下操作:
(1)计算LSO。
Broker在缓存中维护了所有处于运行状态的事务对应的initial offsets,LSO的值就是这些offsets中最小值-1。
举例说明下LSO的计算,对于一个data log中内如如下

对应的abort index文件中内如如下:LSO是递增的

(2)第二步 如果事务是提交状态,则在索引文件中新增TransactionEntry。
(3)第三步 从active的tranaction set中移除这个transaton,然后更新LSO。
4.5.3 问题
1、问题1:producer通过事务提交消息时抛异常了, 对于使用非事务的消费者,是否可以获取此消息?
对于事务消息,必须是执行commit或者abstort之后,消息才对消费者可见,即使是非事务的消费者。只是非事务消费者相比事务消费者区别,在于可以读取执行了absort的消息。
5 其他思考
1、如何保证消息不丢。
(1)在消费端可以建立一个日志表,和业务处理在一个事务
定时扫描没有表发送没有被处理的消息
(2)消费端,消费消息之后,修改消息表的中消息状态为已处理成功。
2、如何保证消息提交和业务处理在同一个事务内完成
在消费端可以建立一个日志表,和业务处理在一个事务
3、消费者角度,如何保证消息不被重复消费。
(1)通过seek操作
(2)通过kafka事务操作。
4、生产者角度,如何保证消息不重复生产
(1)kakfka幂等性
参考资料
【2】Transactional Messaging in Kafka
https://cwiki.apache.org/confluence/display/KAFKA/Transactional+Messaging+in+Kafka
【3】震惊了!原来这才是kafka!https://www.jianshu.com/p/d3e963ff8b70
【4】https://www.confluent.io/blog/transactions-apache-kafka/
【5】消费者如何获取状态为READ_COMMITTED的数据:
https://docs.google.com/document/d/1Rlqizmk7QCDe8qAnVW5e5X8rGvn6m2DCR3JR2yqwVjc/edit
【6】Kafka设计解析(八)- Exactly Once语义与事务机制原理
http://www.jasongj.com/kafka/transaction/
【7】https://hevodata.com/blog/exactly-once-message-delivery-in-kafka/

")

(翻译)")

