目录
原文:https://zhuanlan.zhihu.com/p/106669828
一句话总结为什么深度学习和神经网络需要GPU
深度学习和神经网络的每个计算任务都是独立于其他计算的,任何计算都不依赖于任何其他计算的结果,可以采用高度并行的方式进行计算。而GPU相比于CPU拥有更多独立的大吞吐量计算通道,较少的控制单元使其不会受到计算以外的更多任务的干扰,拥有比CPU更纯粹的计算环境,所以深度学习和神经网络模型在GPU的加持下会更高效地完成计算任务。
研究深度学习和神经网络大都离不开GPU,在GPU的加持下,我们可以更快的获得模型训练的结果。使用GPU和使用CPU的差别在哪里?为什么需要GPU?
一个关于使用Pytorch的教程中对这个问题进行了一个很好的解释,本文内容主要转载自(访问需要科学上网): https://deeplizard.com/learn/video/6stDhEA0wFQ
为了更好地切题,本文对其内容做了一些删改,并增加了GPU与CPU原理结构的部分,此部分是从CPU 和 GPU 的区别是什么? – 虫子君的回答 – 知乎转载看到的,下面是原链接: CPU和GPU的设计区别
全文较长可以直接拉到末尾看一句话总结
CPU和GPU是什么
GPU(Graphics processing unit),中文全称图形处理器,我们听说的更多的CPU全称是central processing unit,中央处理器。
CPU是电子计算机的主要设备之一,电脑中的核心配件。其功能主要是解释计算机指令以及处理计算机软件中的数据。CPU是计算机中负责读取指令,对指令译码并执行指令的核心部件。
GPU(图形处理器)是图形系统结构的重要元件,是连接计算机和显示终端的纽带。一个光栅显示系统离不开图形处理器(GPU)。 应该说有显示系统就有图形处理器,但是早期的显卡只包含简单的存储器和帧缓冲区,它们实际上只起了一个图形的存储和传递作用,一切操作都必须由CPU来控制。这对于文本和一些简单的图形来说是足够的,但是当要处理复杂场景特别是一些真实感的三维场景,单靠这种系统是无法完成任务的。所以后来发展的显卡都有图形处理的功能。它不单单存储图形,而且能完成大部分图形功能,这样就大大减轻了CPU的负担,提高了显示能力和显示速度。
图形处理器可单独与专用电路板以及附属组件组成显卡,或单独一片芯片直接内嵌入到主板上,或者内置于主板的北桥芯片中,现在也有内置于CPU上组成SoC的。个人电脑领域中,在2007年,90%以上的新型台式机和笔记本电脑拥有嵌入式绘图芯片,但是在性能上往往低于不少独立显卡。
GPU的计算速度比CPU快得多。然而,情况并不总是如此。GPU相对于CPU的速度取决于执行的计算类型。最适合GPU的计算类型是可以并行完成的计算。
并行计算
并行计算是一种将特定计算分解成可以同时进行的独立的较小计算的计算方式。然后重新组合或同步计算结果,形成原来较大计算的结果。
更大的任务可以分解成的任务数量取决于特定硬件上包含的内核数量。核心是在给定处理器中实际执行计算的单元,CPU通常有4个、8个或16个核心,而GPU可能有数千个。还有其他重要的技术规范,但是这个描述是用来驱动总体思想的。(此处涉及的原理在CPU和GPU的设计区别)
有了这些工作知识,我们可以得出结论,并行计算是使用GPU完成的,我们还可以得出结论,最适合使用GPU解决的任务是可以并行完成的任务。如果计算可以并行完成,我们可以使用并行编程方法和GPU加速计算。
神经网络是高度并行的(embarrassingly parallel)
现在让我们把注意力转向神经网络,看看为什么GPU在深度学习中被如此频繁地使用。我们刚刚看到,GPU非常适合并行计算,而关于GPU的这个事实就是为什么深度学习要使用它们。神经网络是高度并行的(embarrassingly parallel)。
在并行计算中,高度并行任务是指将整个任务分割成一组较小的任务以并行计算的任务。 高度并行任务是那些很容易看到一组小任务彼此独立的任务。
由于这个原因,神经网络高度并行。我们用神经网络做的许多计算都可以很容易地分解成更小的计算,这样小的计算集就不会相互依赖。一个这样的例子就是卷积。
卷积示例
来看一个卷积运算的例子:
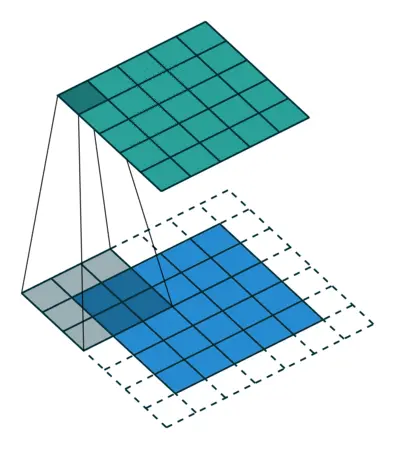
这个动画展示了没有数字的卷积过程。我们在底部有一个蓝色的输入通道。在输入通道上滑动的底部有一个阴影的卷积滤波器,还有一个绿色的输出通道。 – 蓝色(底部)- 输入通道 – 阴影(覆盖在蓝色上)- 3*3的卷积过滤器 – 绿色(顶部)- 输出通道
对于蓝色输入通道上的每个位置,3×3过滤器进行计算,将蓝色输入通道的阴影部分映射到绿色输出通道的相应阴影部分。
在动画中,这些计算一个接一个地依次进行。但是,每个计算都是独立于其他计算的,这意味着任何计算都不依赖于任何其他计算的结果。
因此,所有这些独立的计算都可以在GPU上并行进行,从而产生整个输出通道。
这让我们看到,卷积运算可以通过使用并行编程方法和GPU来加速。
英伟达Nvidia硬件(GPU)和软件(CUDA)
这就是CUDA的用武之地。Nvidia是一家设计GPU的技术公司,他们把CUDA作为一个软件平台,与他们的GPU硬件配对,让开发者更容易构建软件,利用Nvidia GPU的并行处理能力加速计算。
Nvidia GPU是支持并行计算的硬件,而CUDA是为开发者提供API的软件层。
因此,你可能已经猜到Nvidia的GPU需要使用CUDA,而CUDA可以从Nvidia的网站上免费下载和安装。
开发人员通过下载CUDA工具包来使用CUDA。随工具包而来的是专门的库,如cuDNN, CUDA深度神经网络库。
GPU可以比CPU慢
我们说过我们可以选择在GPU或CPU上运行我们的计算,但为什么不直接在GPU上运行所有的计算呢?
答案是GPU只对特定的(专门的)任务更快。我们可能遇到的一个问题是瓶颈,这会降低我们的性能。例如,将数据从CPU移动到GPU是昂贵的,所以在这种情况下,如果计算任务是简单的,那么整体性能可能会变慢。

将相对较小的计算任务转移到GPU不会使我们的速度提高很多,甚至可能降低我们的速度。记住,对于可以分解成许多小任务的任务,GPU工作得很好,如果一个计算任务已经很小了,我们将不会通过将任务转移到GPU来获得很多。
由于这个原因,在刚开始的时候简单地使用CPU通常是可以接受的,当我们处理更大更复杂的问题时,开始更多地使用GPU。
GPGPU计算
一开始,使用gpu加速的主要任务是计算机图形。因此得名图形处理单元,但近年来,出现了更多种类的并行任务。我们所看到的任务之一就是深度学习。
深度学习和许多其他使用并行编程技术的科学计算任务一起,正在导致一种新的编程模型,称为GPGPU或通用GPU计算。
GPGPU计算通常被称为GPU计算或加速计算,现在在GPU上预置各种任务变得越来越普遍。
英伟达是这一领域的先驱。Nvidia将通用GPU计算简称为GPU计算。英伟达首席执行官黄延森(Jensen Huang)很早就预见到了GPU计算,这也是CUDA在近10年前诞生的原因。
虽然CUDA已经存在了很长一段时间,但它现在才刚刚开始真正的飞行,而Nvidia在CUDA上的工作到目前为止是Nvidia在GPU计算深度学习方面领先的原因。
当我们听到Jensen谈到GPU计算堆栈时,他指的是底层的GPU是硬件,底层的CUDA是软件架构,最后是CUDA之上的cuDNN库。
这个GPU计算栈支持通用的计算能力,而通用的计算能力在其他方面是非常专业的。我们经常在计算机科学中看到这样的栈,因为技术是分层构建的,就像神经网络一样。
在CUDA和cuDNN之上的是PyTorch,这是很多人正在使用的最终支持应用程序的框架。
")



")
