目录
本文概览:优化慢查询核心就是优化索引,查看一个查询sql是否用到了索引。还介绍了mysql的索引。
1 优化
1.1 慢查询和索引关系
慢查询主要是通过索引来优化,索引的目的就是为了查询速度增快,但是会减慢增、删、改三种操作,这些操作需要更新索引。
1.2 优化步骤
1、查询时用到索引的地方
关于索引总结,索引是mysql数据库这一块的重点,决定了效率。对于一个简单sql查询语句主要包含:
(1) distinct 【可以用到索引】
(2) where 【可以用到索引】
- 集合比较, in 和 exsit都可以用到索引。但是not in 或者 not exsit用不到索引。
- 文本匹配,like,like ‘name%’可以用到索引
- 数值比较,between=,>=,<=,> , <
(3)order by【可以用到索引】
(4) group by【可以用到索引】
(5) 聚集函数【用不到索引】
2、 使用联合索引和覆盖索引
因为一个表只能用一个索引,所以尽可能使用联合索引。所以在用到and条件的时候就要考虑联合索引
3、 使用覆盖索引
只需要查询索引表,就不需要再查询数据表了。
4、 建立短索引(对应varchar类型)
(1)作用
例如有一个CHAR(255)的列,如果在前10个或20个字符内,多数值是惟一的,那么就不要对整个列进行索引。短索引不仅可以提高查询速度而且可以节省磁盘空间和I/O操作。
(2)建立
key idx_name(name(80));
1.3 order by 优化
1、单表
(1) ORDER BY的索引优化。如果一个SQL语句形如:
|
1 |
SELECT [column1],[column2],.... FROM [TABLE] ORDER BY [sort]; |
在[sort]这个栏位上建立索引就可以实现利用索引进行order by 优化。
(2)WHERE + ORDER BY的索引优化,形如:
|
1 |
SELECT [column1],[column2],....... FROM [TABLE] WHERE [columnX] = [value] ORDER BY [sort]; |
建立一个联合索引(columnX,sort)来实现order by 优化。
注意:如果columnX对应多个值,如下面语句就无法利用索引来实现order by的优化
|
1 |
SELECT [column1],[column2],....... FROM [TABLE] WHERE [columnX] IN ([value1],[value2],.....) ORDER BY[sort]; |
(3)WHERE+ 多个字段ORDER BY
|
1 |
SELECT * FROM [table] WHERE uid=1 ORDER x,y LIMIT 0,10; |
建立索引(uid,x,y)实现order by的优化,比建立(x,y,uid)索引效果要好得多。
2、 多表
将order by 的字段要作为驱动表的字段。
2 索引类型
2.1 索引总结
1. 索引存储形式
分为聚集索引(对于主键建立的索引)和非聚集索引(非主键的索引)。两者不同点在于:
|
1 |
对于聚集索引的叶子节点存储数据位主列值和非主键列值;对于非聚集索引是索引列值和主键值。 |
(1)聚集索引:就是数据在磁盘的排序方式。由于聚集索引规定数据在表中的物理存储顺序,因此一个表只能包含一个聚集索引。(主键索引)
(2)非聚集索引是一种逻辑索引。如对于词典前面按照拼音的目录就是非聚集索引。一般数据库所建立索引是非聚集索引,非聚集索引是独立于磁盘上数据之外建立的一份索引文件。
举例:如没有目录的词典,即只有词典内容是按照聚集索引方式装订。为了快速查找某个词,我们在内容外,构建了非聚集索引:按字母顺序排序的目录。
2. 一个表上操作只能用到一个索引。join操作时,可以用到两个表,此时就可以用两个索引,因为每一个表可以用一个索引。
3. 建立索引的字段不能为null
2.2 主键 primary key
1. 建立唯一键
|
1 |
PRIMARY KEY (`id`) |
2. 对应数据结构
对于建立主键的表来讲,既可以看成是数据表,也可以看成是主键表的索引,所以在主键的索引节点中,保留了所有数据的值,因为它本来就是一个数据表,所以对于每一个记录都要保存所有字段的值,只是建立一个主键之后,可以将表的物理存储形式看成是由B+树实现的基于主键进行排序的数据结构。
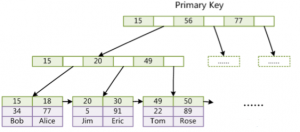
(1)对于聚簇索引的结构,为什么都是将数据节点放在叶子节点?同样对于二级索引,也是将数据放在叶子节点?
因为这样做减少IO磁盘,没有放置数据可以减少每一个索引节点的大小,这样每一个磁盘块就可以放置更多的索引节点,所以一次IO磁盘就会加载更多的索引节点,从而可以减少查询操作时加重索引节点的次数。这也正是B+树引入的目的:B+树就是应文件系统查询而生的一种数据结构。B+树相对于B树一个不同点就是所有数据存储在叶子节点。
2.2 唯一索引uniq
1. 应用场景
当我们需要标识一个字段的值是唯一的时候,此时为了达到这个目的就需要建立唯一索引。
注意:建立唯一索引的数据库字段一默认值不能设置为非空且默认值为空字符串了,只能是非空,因为即使有两个记录都是空字符串时,也会报错。
2、建立唯一索引
如下时建表时建立唯一索引
|
1 |
UNIQUE KEY `uniq_serial_number` (`serial_number`) |
3. 对应数据结构
叶子的数据节存储的是主键数据
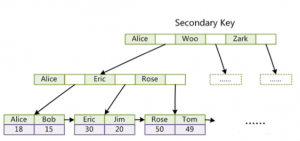
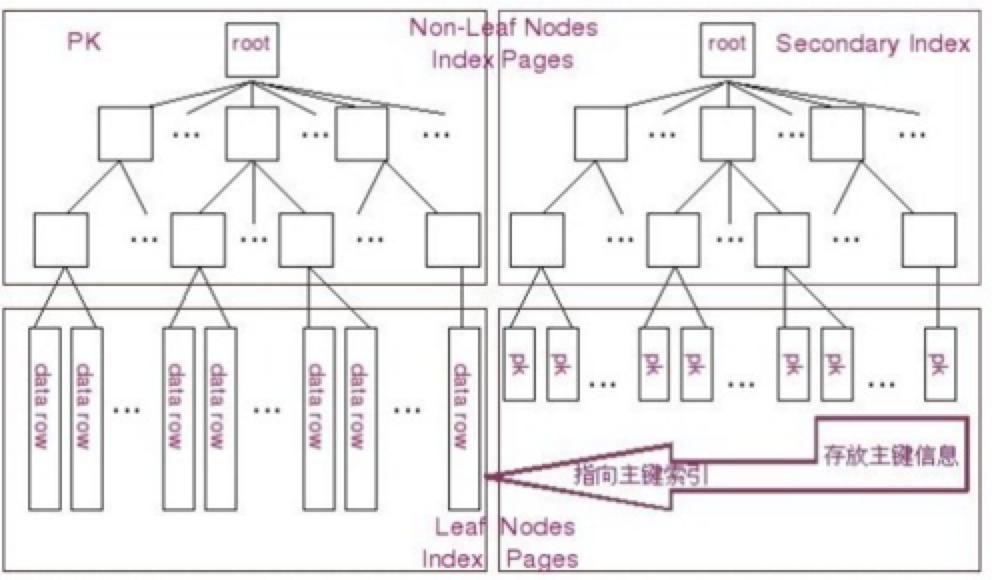
和普通索引数据结构一样,按这种非聚簇索引查询需要两个步骤:
(1)首先,根据这个索引查找到主键值;
(2)然后,根据主键值查找相应的数据
步骤图如下:
2.3 普通索引
1 建立普通索引
KEY idx_aggregation (need_aggregation)
2 .与唯一索引区别
唯一索引与普通索引比较就是对数据表中相关字段多了一个唯一性的约束。执行效率都是一样的。
3. 对应数据结构
同唯一索引。
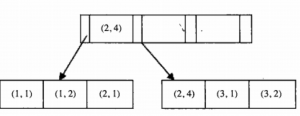
2.4 联合索引
普通索引和唯一索引都可以设置成联合索引。如
|
1 2 3 4 5 |
# 建立唯一的联合索引 UNIQUE KEY `uniq_serial_number_create_time` (`serial_number`,`create_time`), # 建立普通的唯一索引 KEY `idx_serial_number_create_time` (`serial_number`,`create_time`), |
1. 为什么有联合索引
一个查询操作只能使用一个索引。假设我们查询条件中有两个查询条件,如where a = 2 and b >10。此时如果我们分别对a建立了索引,对b建立一个索引,由于上面的理论基础我们可以知道一个查询操作都只能使用一个索引,所以只能用索引a或者索引b。此时如果建立了联合索引,那么此时就会融合两个字段索引效果。
2. 特点
- 特点1:联合索引左前缀是有序的
- 特点2:联合索引前缀的值固定之后(就是必须是等值的情况,不能是范围的:in,like, between,>或者<),此时后缀的值是可以使用索引的,否则不能使用索引
- 特点3:如果前面没有出现,那么后面的不会作为索引
3. 数据结构
2.5 B+树和B树比较
对于B树,将数据data放置在非叶子节点中。
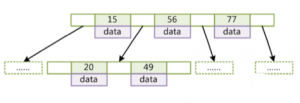
对于B+树,将数据data放置到叶子节点中
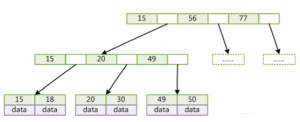
(全文完)
(翻译)")



