目录
原文链接 plan-and-execute/
一、 简介
“计划与执行”(Plan-and-Execute)是一种强大的代理(Agent)设计模式,主要用于解决复杂的多步骤任务。该模式受到 Plan-and-Solve 论文和 Baby-AGI 项目的启发,在LangGraph框架中得到了优雅的实现。
“计划与执行”模式的核心思想:先制定一个多步骤的计划,然后逐项执行该计划。在执行过程中,可以根据新获取的信息动态调整计划。
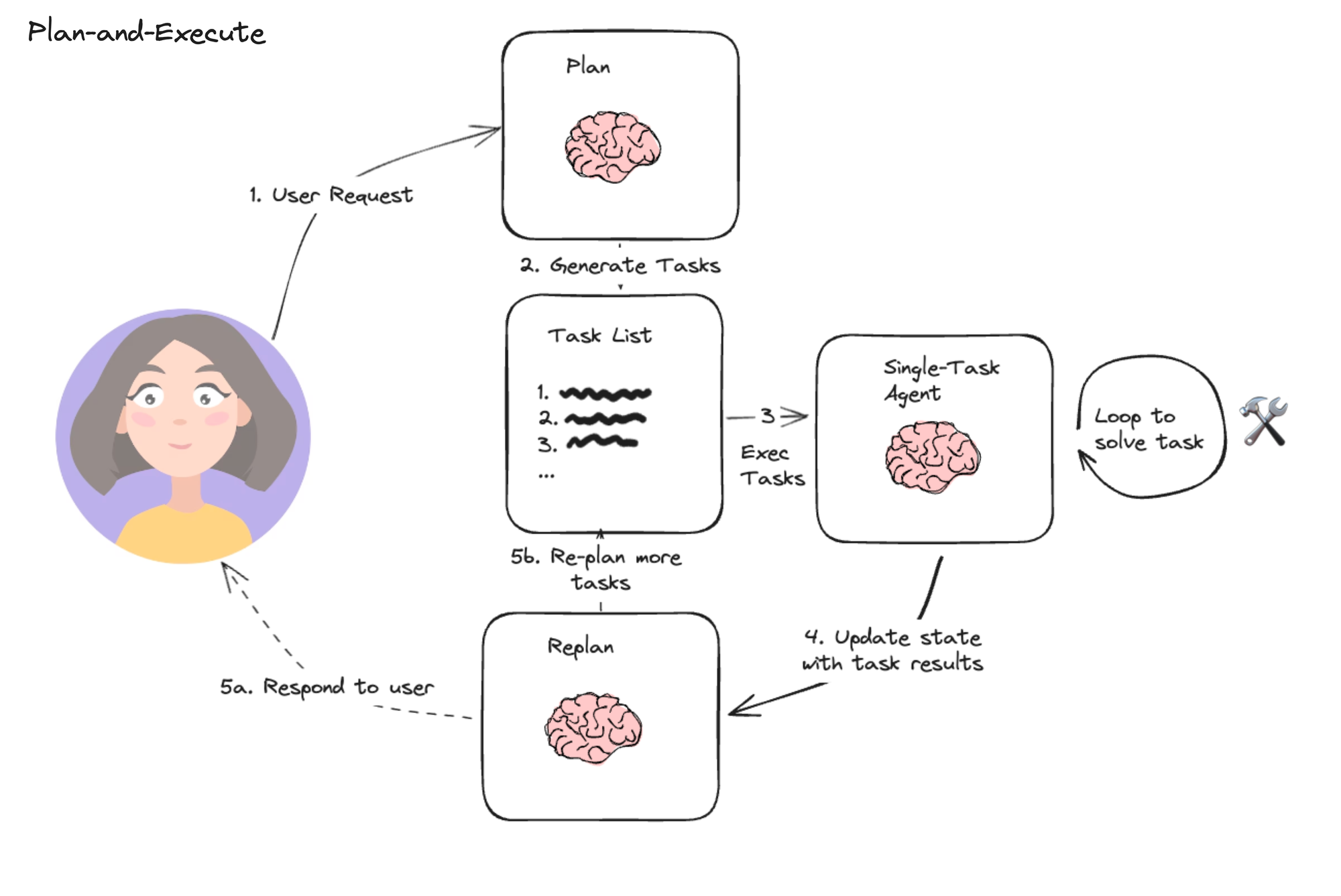
二、 计划与执行模式的原理
1 与ReAct风格代理的区别
ReAct风格代理
-
思考-行动-观察循环进行
-
每次只考虑下一步行动
-
没有明确的长期规划
-
通常使用同一个模型进行思考和行动
计划与执行风格代理
-
先制定完整计划,再逐步执行
-
有明确的长期规划视角
-
可以根据执行结果重新规划
-
可以使用不同模型分别负责规划和执行
2. 计算图概览
“计划与执行”代理的典型计算图如下所示:
-
首先,代理根据用户输入制定初始计划
-
然后,代理执行计划中的第一个步骤
-
基于执行结果,代理重新评估计划
-
如果需要继续执行,则执行下一步骤;如果任务完成,则返回最终响应
这种模式特别适合需要分解为多个步骤的复杂任务,如信息收集、推理和分析等场景。
三、实现步骤详解
1. 环境设置
首先需要安装必要的依赖包:
|
1 |
pip install --quiet -U langgraph langchain-community langchain-openai tavily-python |
设置API密钥:
|
1 2 3 4 5 6 7 8 9 |
import getpass import os def _set_env(var: str): if not os.environ.get(var): os.environ[var] = getpass.getpass(f"{var}: ") _set_env("OPENAI_API_KEY") _set_env("TAVILY_API_KEY") |
2. 定义工具
本例中使用Tavily搜索工具,但您也可以创建自定义工具:
|
1 2 3 |
from langchain_community.tools.tavily_search import TavilySearchResults tools = [TavilySearchResults(max_results=3)] |
工具定义是代理能力的关键组成部分。除了搜索工具外,您还可以根据需要添加计算器、API调用、数据库查询等各种工具,扩展代理的能力范围。
3. 定义执行代理
执行代理负责实际执行计划中的各个步骤:
|
1 2 3 4 5 6 7 |
from langchain_openai import ChatOpenAI from langgraph.prebuilt import create_react_agent # 选择驱动代理的LLM llm = ChatOpenAI(model="gpt-4-turbo-preview") prompt = "You are a helpful assistant." agent_executor = create_react_agent(llm, tools, prompt=prompt) |
这里使用了
create_react_agent函数创建一个ReAct风格的执行代理,它将负责执行计划中的各个具体步骤。4. 定义状态
状态定义了代理在执行过程中需要跟踪的信息:
|
1 2 3 4 5 6 7 8 9 |
import operator from typing import Annotated, List, Tuple from typing_extensions import TypedDict class PlanExecute(TypedDict): input: str # 原始用户输入 plan: List[str] # 当前计划(步骤列表) past_steps: Annotated[List[Tuple], operator.add] # 已执行的步骤及结果 response: str # 最终响应 |
Annotated[List[Tuple], operator.add]表示这个字段在更新时会使用operator.add操作,即新值会被添加到现有列表中,而不是替换整个列表。这对于跟踪执行历史很重要。5. 规划步骤实现
规划步骤负责创建初始计划:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
from pydantic import BaseModel, Field class Plan(BaseModel): """Plan to follow in future""" steps: List[str] = Field( description="different steps to follow, should be in sorted order" ) from langchain_core.prompts import ChatPromptTemplate planner_prompt = ChatPromptTemplate.from_messages( [ ( "system", """For the given objective, come up with a simple step by step plan. \ This plan should involve individual tasks, that if executed correctly will yield the correct answer. Do not add any superfluous steps. \ The result of the final step should be the final answer. Make sure that each step has all the information needed - do not skip steps.""", ), ("placeholder", "{messages}"), ] ) planner = planner_prompt | ChatOpenAI( model="gpt-4o", temperature=0 ).with_structured_output(Plan) |
这段代码定义了:
-
一个
Plan类,用于存储计划步骤 -
一个提示模板,指导LLM如何创建计划
-
一个规划器组件,将提示与LLM和结构化输出结合
6. 重新规划步骤实现
重新规划步骤负责根据执行结果更新计划:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 |
from typing import Union class Response(BaseModel): """Response to user.""" response: str class Act(BaseModel): """Action to perform.""" action: Union[Response, Plan] = Field( description="Action to perform. If you want to respond to user, use Response. " "If you need to further use tools to get the answer, use Plan." ) replanner_prompt = ChatPromptTemplate.from_template( """For the given objective, come up with a simple step by step plan. \ This plan should involve individual tasks, that if executed correctly will yield the correct answer. Do not add any superfluous steps. \ The result of the final step should be the final answer. Make sure that each step has all the information needed - do not skip steps. Your objective was this: {input} Your original plan was this: {plan} You have currently done the follow steps: {past_steps} Update your plan accordingly. If no more steps are needed and you can return to the user, then respond with that. Otherwise, fill out the plan. Only add steps to the plan that still NEED to be done. Do not return previously done steps as part of the plan.""" ) replanner = replanner_prompt | ChatOpenAI( model="gpt-4o", temperature=0 ).with_structured_output(Act) |
这段代码定义了:
-
一个
Response类,用于存储最终响应 -
一个
Act类,可以是新计划或最终响应 -
一个重新规划提示模板,考虑原始目标、原始计划和已执行步骤
-
一个重新规划器组件,将提示与LLM和结构化输出结合
7. 创建计算图
最后,将所有组件连接成一个完整的计算图:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 |
from typing import Literal from langgraph.graph import END async def execute_step(state: PlanExecute): plan = state["plan"] plan_str = "\n".join(f"{i+1}. {step}" for i, step in enumerate(plan)) task = plan[0] task_formatted = f"""For the following plan: {plan_str}\n\nYou are tasked with executing step {1}, {task}.""" agent_response = await agent_executor.ainvoke( {"messages": [("user", task_formatted)]} ) return { "past_steps": [(task, agent_response["messages"][-1].content)], } async def plan_step(state: PlanExecute): plan = await planner.ainvoke({"messages": [("user", state["input"])]}) return {"plan": plan.steps} async def replan_step(state: PlanExecute): output = await replanner.ainvoke(state) if isinstance(output.action, Response): return {"response": output.action.response} else: return {"plan": output.action.steps} def should_end(state: PlanExecute): if "response" in state and state["response"]: return END else: return "agent" from langgraph.graph import StateGraph, START workflow = StateGraph(PlanExecute) # 添加规划节点 workflow.add_node("planner", plan_step) # 添加执行节点 workflow.add_node("agent", execute_step) # 添加重新规划节点 workflow.add_node("replan", replan_step) workflow.add_edge(START, "planner") # 从规划到执行 workflow.add_edge("planner", "agent") # 从执行到重新规划 workflow.add_edge("agent", "replan") workflow.add_conditional_edges( "replan", # 决定下一步去向的函数 should_end, ["agent", END], ) # 编译图 app = workflow.compile() |

四、 图的结构和工作流程
计划与执行模式的图结构包含三个主要节点:
规划节点(planner):负责制定初始计划,将复杂任务分解为一系列可执行步骤。
执行节点(agent):负责执行当前计划中的第一个步骤,并记录执行结果。
重新规划节点(replan):根据执行结果评估计划,决定是继续执行还是返回最终响应。
工作流程如下:
-
从START开始,进入规划节点
-
规划节点创建初始计划后,进入执行节点
-
执行节点执行当前计划的第一个步骤,然后进入重新规划节点
-
重新规划节点根据执行结果决定:
-
如果任务完成,生成最终响应并结束流程
-
如果需要继续执行,更新计划并返回执行节点
-
这种设计使得代理能够自适应地处理复杂任务,根据执行过程中获取的新信息动态调整计划,从而提高任务完成的准确性和效率。
五、优势和局限性
优势
-
明确的长期规划:即使是强大的大型语言模型在长期规划方面也可能遇到困难,而”计划与执行”模式通过显式规划步骤解决了这个问题。
-
模型灵活性:可以在规划步骤使用更强大的模型(如GPT-4),而在执行步骤使用更小/更经济的模型,优化资源使用。
-
可解释性:由于计划是明确定义的,整个过程更加透明和可解释,便于调试和改进。
-
动态适应:通过重新规划步骤,代理可以根据新获取的信息动态调整计划,适应变化的情况。
-
任务分解:将复杂任务分解为更小、更可管理的步骤,提高了处理复杂问题的能力。
局限性
-
顺序执行限制:当前实现中,步骤是按顺序执行的,这可能导致整体执行时间较长。
-
规划质量依赖:整个系统的性能很大程度上依赖于初始规划的质量,如果规划不佳,可能需要多次重新规划。
-
可能的过度规划:对于简单任务,”计划与执行”模式可能引入不必要的复杂性和开销。
-
工具依赖:代理的能力受限于可用工具的范围和功能,需要为不同任务设计适当的工具集。
六、应用场景和改进方向
潜在应用场景
-
复杂信息检索:需要从多个来源收集、综合和分析信息的任务。
-
多步骤推理:需要逐步推理的复杂问题解决,如数学证明、逻辑推理等。
-
自动化研究:自动执行文献综述、数据分析等研究任务。
-
个人助手:处理需要多步骤规划的日常任务,如旅行规划、项目管理等。
-
教育辅助:分解复杂学习任务,为学生提供逐步指导。
可能的改进方向
-
并行执行:将计划表示为有向无环图(DAG)而非线性列表,允许并行执行独立步骤,类似于LLMCompiler的方法。
-
自适应规划:根据任务复杂性动态决定是否需要详细规划,避免简单任务的过度规划。
-
记忆增强:添加长期记忆组件,使代理能够从过去的执行经验中学习。
-
多代理协作:扩展为多个专业代理协作的系统,每个代理负责特定类型的任务。
-
用户交互:在执行过程中添加用户交互点,允许人类提供反馈和指导。
“计划与执行”模式代表了代理系统设计的一个重要方向,通过结合大型语言模型的推理能力和明确的规划结构,为解决复杂任务提供了有效框架。随着技术的发展,我们可以期待这种模式在各种应用场景中的进一步优化和应用。
七、总结
LangGraph的”计划与执行”模式提供了一种强大的方法来构建能够处理复杂多步骤任务的AI代理。通过将任务分解为计划和执行两个主要阶段,并在执行过程中动态调整计划,这种模式克服了传统ReAct代理在长期规划方面的局限性。
虽然当前实现存在一些限制,如顺序执行导致的效率问题,但通过将计划表示为DAG等改进,可以进一步提高系统的性能和灵活性。随着大型语言模型和代理框架的不断发展,”计划与执行”模式有望在各种复杂任务解决场景中发挥越来越重要的作用。
(翻译)")


")

