目录
原文:The “think” tool: Enabling Claude to stop and think in complex tool use situations
一款提升 Claude 复杂问题解决能力的全新工具
在持续增强 Claude 复杂问题解决能力的过程中,我们发现了一种格外有效的方法:一款 “思考”(think)工具,能在复杂任务执行过程中为结构化思考创造专属空间。
这一简单却强大的技术 —— 下文将详细说明其与 Claude 新增的 “扩展思考”(extended thinking)功能的区别 —— 显著提升了 Claude 的智能体工具使用能力,包括遵循规则政策、做出一致性决策、处理多步骤问题等,且实现成本极低。
本文将探讨如何在不同应用中部署 “思考” 工具,并基于经过验证的基准测试结果,为开发者提供实用指导。
1 什么是 “思考” 工具?
借助 “思考” 工具,我们赋予了 Claude 一项能力:在得出最终答案的过程中,新增一个专属的思考步骤。
尽管它听起来与 “扩展思考” 类似,但二者属于不同概念:
- 扩展思考聚焦于 Claude 生成响应之前的行为 —— 在采取行动前,Claude 会深入思考并迭代优化方案;
- “思考” 工具则适用于 Claude开始生成响应后,新增一个 “驻足思考” 的步骤,判断自身是否已掌握继续推进所需的全部信息。这在执行长链工具调用、或与用户进行多步骤长对话时尤为实用。
因此,“思考” 工具更适合以下场景:仅依靠用户查询无法获取足够信息来形成响应,需要处理外部信息(如工具调用结果中的信息)。与扩展思考相比,“思考” 工具的推理过程不够全面,更专注于模型新发现的信息。
我们建议:
对于非连续工具调用、简单指令执行等较简单的工具使用场景,优先使用扩展思考;
对于编码、数学、物理等无需调用工具的场景,扩展思考同样适用;
“思考” 工具更适合以下情况:需调用复杂工具、在长链工具调用中仔细分析工具输出、在规则密集型环境中遵循详细指南、或执行步骤间相互依赖且错误成本高的连续决策。
以下是基于 τ-Bench 标准工具规范格式的示例实现:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ "name": "think", "description": "Use the tool to think about something. It will not obtain new information or change the database, but just append the thought to the log. Use it when complex reasoning or some cache memory is needed.", "input_schema": { "type": "object", "properties": { "thought": { "type": "string", "description": "A thought to think about." } }, "required": ["thought"] } } |
2 在 τ-Bench 基准测试中的表现
我们通过 τ-Bench(tau-bench)对 “思考” 工具进行了评估。该基准测试专为检验模型在真实客服场景中的工具使用能力而设计,“思考” 工具是其评估标准环境的一部分
τ-Bench 主要评估 Claude 的以下能力:
- 与模拟用户进行真实对话;
- 持续遵循复杂的客服智能体规则指南;
- 使用多种工具访问和操作环境数据库。
τ-Bench 采用的核心评估指标是 pass^k,衡量特定任务在 k 次独立测试中全部成功的概率(取所有任务的平均值)。与其他 LLM 评估中常用的 pass@k 指标(衡量 k 次测试中至少一次成功的概率)不同,pass^k 更注重一致性和可靠性 —— 这对于需严格遵守规则的客服类应用至关重要。
2.1 性能分析
我们对比了多种配置的表现:
- 基准组(无 “思考” 工具,无扩展思考模式);
- 仅启用扩展思考模式;
- 仅启用 “思考” 工具;
- “思考” 工具 + 优化提示词(针对航空领域)。
结果显示,当 Claude 3.7 有效使用 “思考” 工具时,在基准测试的 “航空” 和 “零售” 两大客服领域均实现了显著提升:
- 航空领域:“思考” 工具 + 优化提示词的配置在 pass^1 指标上达到 0.570,远高于基准组的 0.370,相对提升 54%;
- 零售领域:仅启用 “思考” 工具便达到 0.812,高于基准组的 0.783。
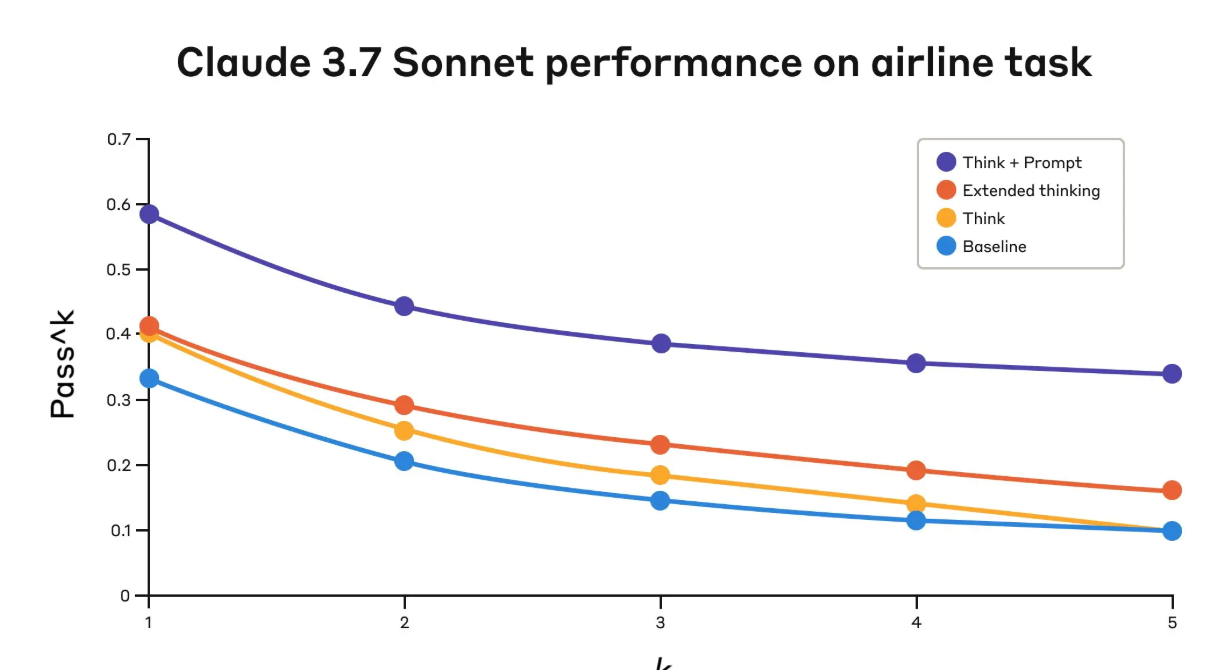
表 1:Claude 3.7 Sonnet 在 τ-Bench 航空领域的表现(不同配置)
| 配置 | k=1 | k=2 | k=3 | k=4 | k=5 |
|---|---|---|---|---|---|
| “思考” 工具 + 提示词 | 0.584 | 0.444 | 0.384 | 0.356 | 0.340 |
| 仅 “思考” 工具 | 0.404 | 0.254 | 0.186 | 0.140 | 0.100 |
| 仅扩展思考 | 0.412 | 0.290 | 0.232 | 0.192 | 0.160 |
| 基准组 | 0.332 | 0.206 | 0.148 | 0.116 | 0.100 |
在航空领域,表现最佳的配置是 “思考” 工具 + 优化提示词 —— 该提示词提供了分析用户请求时的推理示例。以下是优化提示词的示例:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 |
## 使用思考工具的指南 在接收工具结果后采取任何行动或回复用户前,请使用思考工具作为草稿本,完成以下事项: - 列出适用于当前请求的具体规则; - 检查是否已收集所有必要信息; - 验证计划的行动是否符合所有政策; - 反复核对工具结果的准确性。 以下是思考工具的使用示例: <<think_tool_example_1> 用户希望取消航班ABC123 - 需验证:用户ID、预订ID、取消原因; - 核对取消规则: * 是否在预订后24小时内? * 若否,核对客票等级及保险情况; - 确认无已使用或过期的航段; - 计划:收集缺失信息→验证规则→获取确认。 </</think_tool_example_1> <<think_tool_example_2> 用户希望预订3张前往纽约的机票,每人2件托运行李 - 需用户ID以核对: * 会员等级(影响行李额度); * 账户中可用的支付方式; - 行李费用计算: * 经济舱×3名乘客; * 普通会员:每人1件免费行李→额外3件,费用150美元; * 银卡会员:每人2件免费行李→无额外费用; * 金卡会员:每人3件免费行李→无额外费用; - 需验证的支付规则: * 最多可使用1张旅行券、1张信用卡、3张礼品卡; * 所有支付方式必须已绑定账户; * 旅行券余额不找零; - 计划: 1. 获取用户ID; 2. 验证会员等级以计算行李费; 3. 核对账户中的支付方式及组合是否合规; 4. 计算总费用:机票费+行李费(如有); 5. 获取用户的明确预订确认。 </</think_tool_example_2> |
不同方案的对比结果颇具启发:
- “思考” 工具 + 优化提示词的表现显著优于扩展思考模式(后者与未加提示词的 “思考” 工具表现相近);
- 仅启用 “思考” 工具(无提示词)虽比基准组有所提升,但仍不及优化配置。
“思考” 工具与优化提示词的组合之所以表现最佳,很可能是因为航空领域的政策复杂度极高,模型从 “思考示例” 中获益良多。
表 2:Claude 3.7 Sonnet 在 τ-Bench 零售领域的表现(不同配置)
| 配置 | k=1 | k=2 | k=3 | k=4 | k=5 |
|---|---|---|---|---|---|
| 仅 “思考” 工具 | 0.812 | 0.735 | 0.685 | 0.650 | 0.626 |
| 仅扩展思考 | 0.770 | 0.681 | 0.623 | 0.581 | 0.548 |
| 基准组 | 0.783 | 0.695 | 0.643 | 0.607 | 0.583 |
在零售领域,即便未添加额外提示词,“思考” 工具仍实现了 0.812 的最高 pass^1 分数。由于零售领域的政策比航空领域更易理解,Claude 仅需一个专属的思考空间,无需额外指导即可实现性能提升。
2.2 τ-Bench 分析的核心洞察
详细分析揭示了以下有助于有效部署 “思考” 工具的规律:
- 提示词对复杂领域至关重要:仅提供 “思考” 工具虽能小幅提升性能,但在复杂领域中,搭配优化提示词可实现质的飞跃;而较简单的领域仅需启用 “思考” 工具即可获益;
- 提升跨测试的一致性:“思考” 工具带来的性能提升在 k=5 的 pass^k 指标中仍保持稳定,表明该工具能帮助 Claude 更有效地处理边缘案例和特殊场景。
3 在 SWE-Bench 基准测试中的表现
我们在 SWE-Bench 测试环境中也为 Claude 3.7 Sonnet 添加了类似的 “思考” 工具,助力其实现了 0.623 的最先进分数。以下是适配后的 “思考” 工具定义:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
{ "name": "think", "description": "使用该工具进行思考。它不会获取新信息或修改代码仓库,仅记录思考内容。适用于需要复杂推理或头脑风暴的场景。例如:探索代码仓库后发现bug根源时,调用该工具构思多种独特的修复方案,并评估哪种(或哪些)修改最简单有效;或收到测试结果后,思考如何修复失败的测试用例。", "input_schema": { "type": "object", "properties": { "thought": { "type": "string", "description": "你的思考内容" } }, "required": ["thought"] } } |
实验结果(使用 “思考” 工具的 30 个样本 vs 未使用的 144 个样本)显示:仅添加该工具就使平均性能提升了 1.6%(Welch’s t 检验:t (38.89) = 6.71,p < .001,d = 1.47)。
4 何时使用 “思考” 工具?
基于上述评估结果,我们总结了 Claude 最能从 “思考” 工具中获益的场景:
- 工具输出分析:需仔细处理之前的工具调用结果才能采取行动,且可能需要回溯调整方案;
- 规则密集型环境:需遵循详细指南并验证合规性;
- 连续决策:每个行动都建立在之前的步骤之上,且错误成本高(常见于多步骤领域)。
5 实现最佳实践
基于 τ-Bench 实验,我们推荐以下 “思考” 工具的实现方案,以最大化其效果:
1、提供含领域特定示例的策略性提示词:最有效的方式是明确说明 “思考” 工具的使用时机和方法(如 τ-Bench 航空领域的示例)。提供贴合具体使用场景的示例,能显著提升模型对工具的运用效果,包括:
- 推理过程的预期详细程度;
- 如何将复杂指令拆解为可执行步骤;
- 处理常见场景的决策树;
- 如何检查是否已收集所有必要信息。
2、将复杂指南纳入系统提示词:我们发现,若 “思考” 工具的使用说明较长或较复杂,将其置于系统提示词中比写入工具描述更有效。这种方式能提供更全面的上下文,帮助模型更好地将思考过程融入整体行为。
6. 何时不建议使用 “思考” 工具?
尽管 “思考” 工具能带来显著提升,但并非适用于所有工具使用场景,且会增加提示词长度和输出令牌(token)成本。具体而言,在以下场景中,“思考” 工具无法带来收益:
- 非连续工具调用:若 Claude 仅需一次工具调用或多个并行调用即可完成任务,添加 “思考” 工具不会带来改善;
- 简单指令执行:若无需严格遵守过多约束,且 Claude 的默认行为已能满足需求,额外的 “思考” 步骤不会带来增益。
七、入门指南
“思考” 工具的部署流程简单,仅需几步即可实现显著提升:
- 针对智能体工具使用场景进行测试:从具有挑战性的场景入手 —— 即 Claude 目前在规则合规性、长链工具调用中的复杂推理方面存在不足的场景;
- 添加工具定义:实现适配自身领域的 “思考” 工具,代码量极少,但能支持更结构化的推理。同时,可在系统提示词中添加工具使用说明及领域相关示例;
- 监控与优化:观察 Claude 在实际场景中对工具的使用情况,调整提示词以鼓励更有效的思考模式。
该工具的最大优势在于:性能损耗极小 —— 除非 Claude 主动使用,否则不会改变外部行为,也不会干扰现有工具或工作流。
8 结论
我们的研究表明,“思考” 工具能显著提升 Claude 3.7 Sonnet 在复杂任务中的表现 ¹—— 尤其是那些需要遵守规则、在长链工具调用中进行推理的任务。“思考” 工具并非万能解决方案,但在适配的场景中能带来巨大价值,且实现复杂度极低。
我们期待看到开发者借助 “思考” 工具,用 Claude 构建出更强大、更可靠、更透明的 AI 系统。
注 1:尽管我们的 τ-Bench 测试结果聚焦于 Claude 3.7 Sonnet 的性能提升,但实验表明,Claude 3.5 Sonnet(新版)在相同配置下也能实现性能增益,这意味着该改进适用于其他 Claude 模型。
(翻译)")


