目录
看不懂 “跑分”?一文读懂 Benchmark 是什么、怎么看、怎么用
刚接触 AI 大模型,你可能会被各种 “跑分”、“榜单” 和 “Benchmark” 搞得眼花缭乱。为什么有的模型自称 “全球第一”,在另一个榜单上却表现平平?这些分数对我们普通用户和开发者来说,到底意味着什么?
别担心,这份指南将用最通俗的语言,带你一步步揭开大模型评测(Benchmark)的神秘面纱,让你轻松看懂模型的真实能力。
什么是 “大模型评测(Benchmark)”?
简单来说,大模型评测(Benchmark)就是一套标准化的 “考卷”,用来衡量和比较不同 AI 大模型的能力。
想象一下,每个大模型都是一个学生,它们知识渊博、能力各异。为了知道哪个学生更擅长数学,哪个更擅长写作,我们就需要用同一套数学题和作文题来测试它们。这套标准化的考题,就是 Benchmark。
为什么我们需要评测?
- 衡量能力:客观地了解一个模型在特定任务(如代码、翻译、常识问答)上的表现如何。
- 促进发展:为模型开发者提供明确的优化目标,推动整个领域的技术进步。
- 辅助决策:帮助企业和个人根据自己的需求(如开发应用、学术研究),选择最合适的模型。
评测、排行榜和宣传分数,有什么区别?
Benchmark (评测基准):指 “考卷” 本身,即数据集、评估方法和指标的集合。它是中立的、可复现的。
Leaderboard (排行榜):是 “成绩单公示栏”。它收集不同模型在同一个 Benchmark 上的得分,并进行排名。不同榜单可能因为测试细节不同,导致同一模型排名各异。
宣传分数:通常是模型厂商选择性展示的 “最高分”。可能只强调了模型最擅长的几个评测,而忽略了其他方面的表现。需要辩证看待。
谁会关心评测?
- 学术研究者:关注模型的综合能力、推理极限和技术边界,常用通识和代码评测。
- 产品开发者:关注模型在具体业务场景下的表现,如客服问答、内容生成,更关心真实任务评测。
- 运维工程师: 关注模型的运行效率和成本,如响应速度(延迟)、服务容量(吞吐量)和费用。
常见的评测 “考卷” 有哪些?
评测集五花八门,这里介绍几类最具代表性的 “考卷”,让你有个直观感受。
通识知识与考试类
这类评测像 “百科知识竞赛” 或 “高考”,考察模型的知识广度和基础能力。
| 评测集 | 简介 |
| MMLU | 最经典的综合能力评测,包含 57 个科目(如历史、数学、法律)的大学水平选择题。 |
| C-Eval / CMMLU | MMLU 的 “中文版”,覆盖从初中到大学的 52 个学科,更贴近中文语言和文化背景。 |
| Gaokao-Bench | 用中国高考题来测试模型,题目难度高,综合性强。 |
代码与推理类
这类评测像 “编程大赛” 和 “奥数竞赛”,挑战模型的逻辑推理和代码生成能力。
| 评测集 | 简介 |
| HumanEval / MBPP | 经典的 Python 代码生成评测,给定函数描述,让模型写出能通过单元测试的代码。 |
| GSM8K / MATH | 数学应用题评测,需要模型理解题目、进行多步推理并给出正确答案。 |
| Big-Bench Hard | 一组极具挑战性的推理任务,人类都难以轻松解决,用于测试模型的推理能力上限。 |
对话与综合能力
这类评测像 “辩论赛” 或 “用户体验评分”,关注模型对话的流畅性、有用性和人类偏好。
| 评测集 | 简介 |
| MT-Bench | 模拟用户在 8 个维度(写作、角色扮演、推理等)提出多轮对话问题,由更强的模型(如 GPT-4)打分。 |
| Chatbot Arena | “聊天机器人竞技场”,让用户与两个匿名模型对话,然后投票选出更好的那个。通过类似下棋的 Elo 积分系统进行排名。 |
安全与对齐
这类评测像 “品德与安全考试”,考察模型是否会产生有害、不真实或偏见内容。
| 评测集 | 简介 |
| Safety Benchmarks | 向模型提出诱导性问题,看它是否会生成不安全、歧视性或违法内容。 |
| TruthfulQA | 测试模型在回答问题时是复述错误信息,还是承认自己不知道,以此衡量其 “诚实度”。 |
| Hallucination Eval | 评估模型 “一本正经胡说八道”(即幻觉)的倾向,例如在总结文章时是否会捏造事实。 |
多模态(图文理解)
这类评测考察模型同时理解图像和文字的能力。
| 评测集 | 简介 |
| MMMU | 多模态领域的 “MMLU”,包含大学水平的多学科图文问答题。 |
| MathVista | 视觉数学推理,需要模型看懂图表、几何图形并解决数学问题。 |
| DocVQA | 文档视觉问答,让模型阅读文档截图(如发票、报告)并回答相关问题。 |
评测指标
看懂了 “考卷”,还要知道 “分数” 是怎么计算的。
基础能力指标
- – 准确率 (Accuracy): 最常见的指标。在选择题、判断题中,答对的题占总题数的比例。
- – Exact Match (EM): 要求模型生成的内容与标准答案一字不差。非常严格,多用于短答案问答。
- – BLEU / ROUGE: 用于评估翻译、摘要等任务。通过比较模型生成文本与参考答案的词语重合度来打分,不要求完全一致。
- – pass@k: 代码生成专用。指模型生成 k 次代码,其中至少有一次能通过所有测试用例的概率。pass@1 最能反映模型单次生成代码的可靠性。
- – Win Rate / Elo: 人类偏好评测指标。Win Rate 指模型在 “二选一” 对战中的胜率;Elo 是源自国际象棋的等级分系统,胜率越高,分数越高。
生产级关注指标
当模型要用于实际产品时,除了效果,效率和成本也至关重要。
- – 延迟 (Latency): 从发送请求到收到完整回复所需的时间。越低越好,直接影响用户体验。
- – 吞吐量 (Throughput): 服务器在单位时间内能处理的请求数量。越高表示服务能力越强。
- – 上下文长度 (Context Length): 模型能一次性处理的文本长度。越长表示能处理更复杂的任务和更长的对话历史。
- – 成本 (Cost): 调用模型服务的费用,通常按 Token(可以理解为词或字)数量计算。是决定产品能否大规模应用的关键因素。
小白如何上手做评测?
想亲手试试?别怕,评测不只是专家的事。下面是一个简化的上手流程。
STEP1 确定目标
你评测是为了什么?是想找个最会写代码的模型,还是想找个性价比最高的模型来做客服?目标决定了你后续的选择。
STEP2 选择基准
根据目标选择合适的 “考卷”。写代码就选 HumanEval,做中文问答就选 C-Eval,或者干脆用自己业务场景的真实问题。
STEP3 固定参数
为了公平,所有 “考生” 必须在同等条件下考试。固定模型的版本、日期,以及重要的超参数,如温度(Temperature)、随机种子(Seed)和提示词(Prompt)。
STEP4 执行与记录
使用评测工具(如 lm-evaluation-harness)或自己编写脚本,让模型回答问题并自动/手动评分。详细记录结果,以便复现和分析。
评测避坑指南:关键注意事项
高分不等于好用。评测中有很多 “坑”,理解它们能帮你更客观地看待分数。
⚠️ 评测中的常见 “陷阱”
- – 数据污染 (Data Contamination): 如果模型在训练时已经 “刷过” 评测的题目,那它在考试时就相当于作弊,分数再高也无法反映真实能力。
- – 复现性差: 如果不固定模型版本、温度等参数,每次评测的结果都可能不一样,分数也就失去了意义。
- – Prompt 敏感性: 同样的问题,换一种问法(Prompt),模型的回答可能天差地别。好的评测应该考虑这一点。
- – 样本量不足: 只用十几道题来评测一个模型,结果很可能是偶然的,不具备统计显著性。
- – 文化与语言偏差: 英文评测集无法完全衡量模型在中文语境下的表现。例如,它不懂中国的网络流行语或文化典故。
- – 榜单高分 ≠ 落地好用: 通用榜单上的高分模型,在你的特定业务场景(如医疗咨询、法律文书)中可能表现不佳。最终还是要通过真实任务来检验。
如何选择合适的评测?
没有最好的评测,只有最合适的评测。你的目标决定了你的选择。
- 学术对比:关注通用能力,选择 MMLU、GSM8K 等公开、权威的基准,与学术界对齐。
- 产品落地:构建自己的领域任务集。从真实业务中抽取问题,如 “用户最常问的 100 个问题”。
- 运维监控:关注效率和成本指标,持续监控延迟、吞吐量、成本和模型效果是否发生 “漂移”。
- 安全合规: 使用专门的安全评测集,模拟恶意提问(“越狱”),检查模型是否会产生有害或隐私泄露内容。
实战演练:从零搭建一个简单的评测
理论结合实践,我们来模拟一个客服问答场景的评测搭建过程。
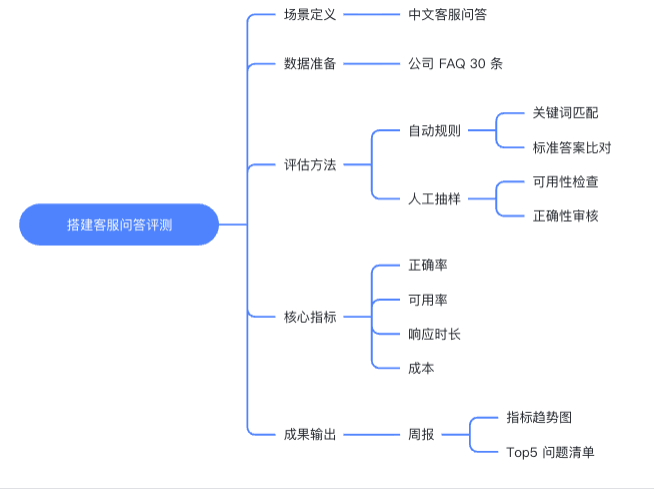
下面对上图的步骤进行详细说明:
1. 场景定义:我们的目标是评估模型在 “中文客服问答” 场景下的表现。
2. 数据准备:从公司内部知识库或历史对话中,整理出 30 条最常见、最具代表性的问题作为 “考题”。
3. 评估方法:结合自动和人工。对于有标准答案的问题,用关键词匹配等自动规则判断;对于开放性问题,人工抽样检查回答是否 “可用” 且 “正确”。
4. 核心指标:
– 正确率:回答内容是否准确。
– 可用率:回答是否解决了用户问题,即使不完全正确。
– 平均响应时长:用户体验关键指标。
– 每千问成本:衡量规模化应用的经济性。
5. 成果输出:制作一个简单的周报,用图表展示各项指标的变化趋势,并列出回答错误率最高的 Top 5 问题,用于持续改进。
常见工具与资源
想要深入探索,以下工具和资源可以帮助你。
| 类别 | 资源 | 简介 |
| 开源评测工具 | lm-evaluation-harness, Openai Evals, Lighteval, HELM, EvalScope | 用于在本地或服务器上运行标准化评测的框架 |
| 在线排行榜 | Chatbot Arena, Open LLM Leaderboard, C-Eval | 查看各大模型最新 “跑分” 的地方。 |
| 数据集 | Papers with Code, Hugging Face Datasets | 寻找和下载评测数据集的平台。 |
术语小词典
快速回顾一下今天学到的关键术语。
- Benchmark: 评测基准,一套标准的 “考卷”。
- Leaderboard: 排行榜,“成绩单公示栏”。
- Win Rate: 胜率,在 “二选一” 对战中的获胜比例。
- Elo: 等级分,用于衡量相对强弱的积分系统。
- pass@k: 代码评测指标,生成 k 次代码的成功率。
- Contamination: 数据污染,模型训练时见过考题。
- Hallucination: 幻觉,“一本正经地胡说八道”。
- E2E 评测: 端到端评测,从用户输入到最终输出的完整流程评测。
FAQ(小白常见问题)
🤔 为什么不同榜单上,同一个模型的分数和排名不一样?
因为各榜单的评测细节可能不同:比如使用的模型版本、提示词(Prompt)的写法、温度等超参数设置、甚至评测框架的代码实现都有差异。因此,对比分数时要确保是在完全相同的评测条件下。
🤔 我只做中文业务,用 MMLU(英文评测)有意义吗?
有参考意义,但价值有限。MMLU 能反映模型的基础知识和推理能力,但无法衡量其对中文特有语言、文化和知识的理解。对于中文业务,应优先参考 C-Eval、CMMLU 等中文评测,并最好构建自己的业务评测集。
🤔 评测时温度(Temperature)设为多少才算公平?
通常设为 0。温度控制着模型回答的随机性,温度越高,回答越具创造性但也越不稳定。为了保证结果的可复现性,进行标准化评测时,通常将温度设为 0 或一个极小的值,以获得最确定性的输出。
🤔 需要多少道题的评测才 “有统计意义”?
这取决于评测的难度和模型的区分度。一般来说,几百到几千道题可以提供比较可靠的结果。如果只用几十道题,模型的得分可能受运气影响很大,偶然答对或答错几道题就会显著影响最终分数。
🤔 如何判断模型的 “幻觉” 下降了?
通过专门的幻觉评测集。这类评测集包含两类任务:一是事实核查,给模型一段包含错误信息的文本,看它能否识别;二是有倾向性的提问,诱导模型在知识范围外进行猜测。通过对比模型在这些任务上 “捏造事实” 的频率,就可以量化其幻觉水平。



和 ReAct")

