目录
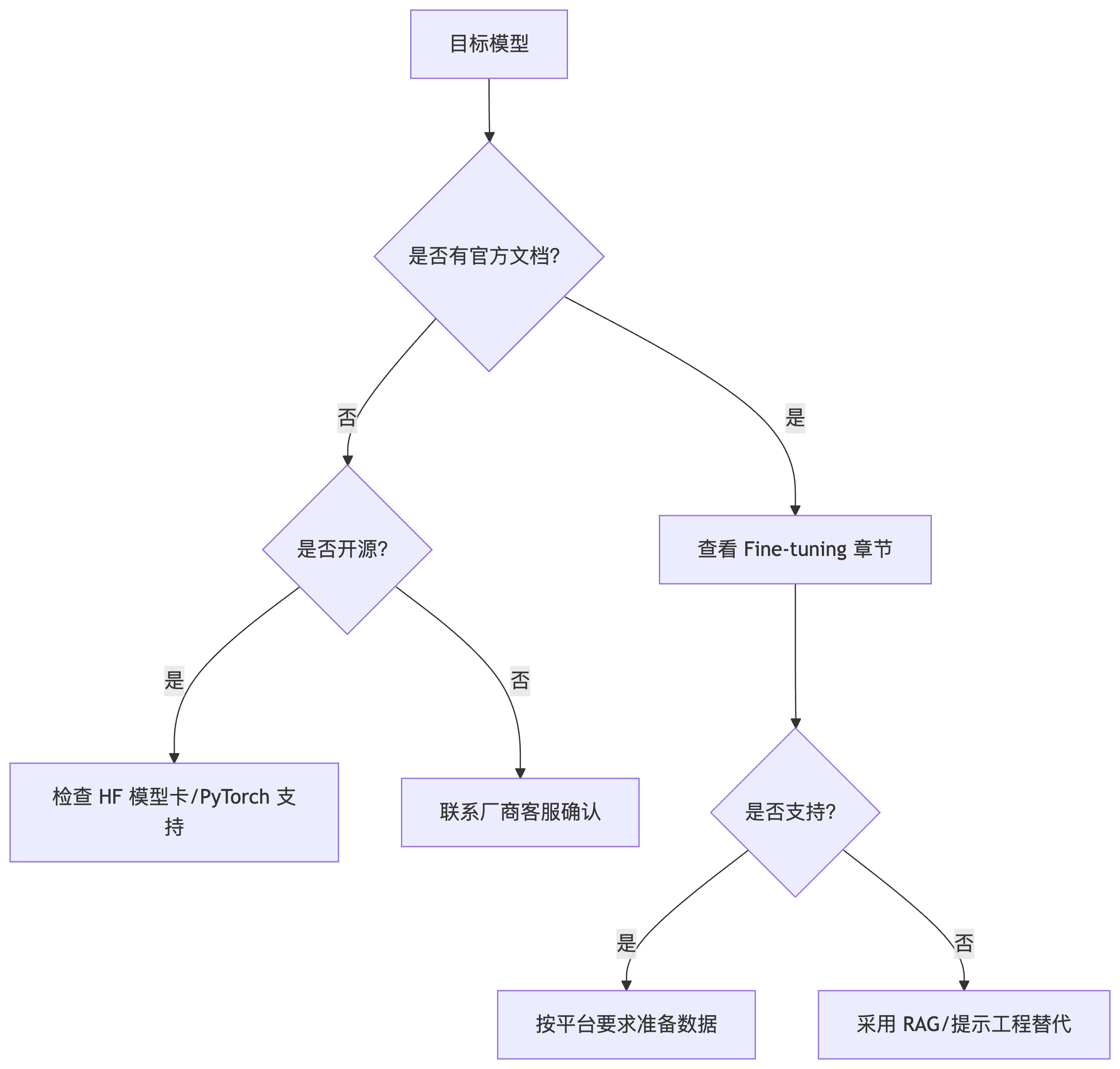
要判断一个大模型是否支持微调(Fine-Tuning),可通过以下 6 个关键步骤 进行系统性验证,涵盖开源模型、闭源商业模型及云平台场景:
1. 查阅官方文档(首要途径)
-
闭源模型(如 GPT-4, Claude, Gemini)
查看开发者文档的 「模型能力」 或 「定制化」 章节:-
✅ OpenAI:明确标注支持微调的模型(如
gpt-3.5-turbo-0125) -
✅ Anthropic:仅 Claude 3 Haiku 在 Amazon Bedrock 开放微调
-
❌ Google Gemini:截至 2024.7 暂不支持 微调
-
-
开源模型(如 LLaMA, Mistral)
在 Hugging Face 或 GitHub 仓库的 README 中搜索关键词:
2. 检查技术架构兼容性
支持微调的模型通常具备以下特征:
-
架构公开性:开源模型(如 LLaMA-2, Yi)可直接下载权重
-
训练框架适配:
-
支持 PyTorch
Trainer/DeepSpeed -
兼容微调库(如 Hugging Face
TRL,Axolotl)
-
-
参数可调性:确认是否开放 全参数微调 或 参数高效微调(PEFT)如 LoRA
3. 验证云平台服务支持
商业模型常通过云平台开放微调:
| 平台 | 支持微调的模型 | 入口位置 |
|---|---|---|
| AWS Bedrock | Claude 3 Haiku | 控制台 > Model access 申请 |
| Azure OpenAI | GPT-3.5-Turbo, GPT-4 (部分版本) | Azure Portal > Fine-tuning jobs |
| Google Vertex AI | PaLM 2 (Text-Bison) | 需提交白名单申请 |
4. 运行代码探测(针对开源模型)
使用 Hugging Face 库快速测试:
|
1 2 3 4 5 6 7 8 |
from transformers import AutoModelForCausalLM try: # 尝试加载支持因果语言建模的模型 model = AutoModelForCausalLM.from_pretrained("模型ID") print("✅ 支持微调:可通过 Trainer 或 PEFT 库训练") except ValueError: print("❌ 模型架构未注册或未开放训练支持") |
5. 识别限制条件
即使技术可行,也需注意限制:
-
商业许可:如 Meta LLaMA-2 允许微调,但商用需申请
-
算力要求:
-
175B 参数模型需 8×A100 80G GPU(全参数微调)
-
7B 模型用 QLoRA 可在 24GB GPU 运行
-
-
数据格式:API 微调通常要求 JSONL(如 OpenAI 格式)
6. 替代方案验证
当官方未开放微调时,可考虑:
-
提示工程:通过
system prompt注入知识(Claude 3 Opus 适用) -
RAG:连接外部知识库(所有对话模型通用)
-
蒸馏微调:用大模型生成数据,微调小模型(如 Claude → Zephyr)
快速决策流程图
各主流模型支持状态(截至 2024.7)
| 模型 | 微调支持 | 接入方式 |
|---|---|---|
| GPT-4 Turbo | ❌ | 仅 API 调用 |
| Claude 3 Haiku | ✅ | AWS Bedrock |
| LLaMA-3 70B | ✅ | Hugging Face + 自建环境 |
| Gemini 1.5 Pro | ❌ | Google AI Studio |
| Mixtral 8x7B | ✅ | 本地部署 / 云 GPU 服务 |
💡 实践建议:优先选择 开源模型(如 Mistral、LLaMA-3)或 明确开放微调的 API 模型(如 Claude 3 Haiku),避免在不可微调的模型上浪费时间。


(翻译)")
