本文总结: 解答了TCP 粘包是什么、原因以及如何解决的问题。
1. 粘包概念
TCP粘包网上说是伪命题,如何理解粘包概念? TCP粘包不是TCP协议的问题,是使用TCP协议发送数据一个现象。现象为:发送方发送的若干包数据到达接收方时粘成了一包。举例如:write()/send() 重复执行三次,每次都发送字符串”abc”,那么目标机器上的 read()/recv() 可能分三次接收,每次都接收”abc”;也可能分两次接收,第一次接收”abcab”,第二次接收”cabc”;也可能一次就接收到字符串”abcabcabc”。
2. “粘包”原因
send和recv操作的是内核soccket缓存区数据,内核TCP协议议模块把socket缓存区的数据加上TCP/IP报文头,通过网卡发送客户端,所以在执行多次send操作,只是保存数据到socket缓存区,最终发送数据跟TCP协议有关:流控、拥塞控制、MSS大小。
3. 如何解决粘包问题?
其实可以把这个问题转换为 如何设计应用层协议的问题, 即如何将TCP流 解码为 报文数据(stream2datagram)。
- HTTP如何设计协议的流到报文的编/解码? 报文header(指定body长度、编码等信息) + 报文body
- Netty如何设计协议的流到报文的编/解码?四种方案如下:
- LineBasedFrameDecoder:以行为单位对数据流进行解码
- DelimiterBasedFrameDecoder:以特殊的符号作为分隔符来对数据流进行解码
- FixedLengthFrameDecoder:以固定长度对数据流进行解码;
- LenghtFieldBasedFrameDecode:适用于消息头包含消息长度的协议
1 粘包所要表达的含义
1.1 引用
文章:https://www.zhihu.com/question/20210025/answer/1096399109
这个词很形象啊哈哈哈。我猜最开始发明这个词的人也是很懵逼吧:我客户端调用了两次send,怎么服务器端一个recv就都读出来了?!怎么回事我辛辛苦苦打包的数据都连在一起了?!啊一定是万恶的TCP偷偷的把我的数据都地粘在一起了(想象中电脑里TCP小人坏笑着拿胶水把数据粘在一起)
TCP本来就是基于字节流而不是消息包的协议,它自己说的清清楚楚:我会把你的数据变成字节流发到对面去,而且保证顺序不会乱,数据不会丢失,但是你要自己搞定字节流解析。所以这个问题其实就是“如何设计应用层协议的问题”。
 TCP本身就是个面向流的协议,如果你要用它传输数据报datagram(比如一次RCP或HTTP请求),必然要自己实现stream2datagram的过程。
TCP本身就是个面向流的协议,如果你要用它传输数据报datagram(比如一次RCP或HTTP请求),必然要自己实现stream2datagram的过程。- 由于tcp是面向流的协议,不会按照应用开发者的期望保持send输入数据的边界,导致接收侧有可能一下子收到多个应用层报文,需要应用开发者自己分开,有些人觉得这样不合理(那你为啥不用udp),起了个名叫“粘包”。
- 用户数据被tcp发出去的时候,存在多个小尺寸数据被封装在一个tcp报文中发出去的可能性。这种“粘”不是接收侧的效果,而是由于Nagle算法(或者TCP_CORK)的存在,在发送的时候,就把应用开发者多次send的数据,“粘”在一个tcp报文里面发出去了,于是,先被send的数据可能需要等待一段时间,才能跟后面被send的数据一起组成报文发出去。
这两个其实都不是“问题”:
- 第一个是tcp的应有之义,人家本身就是个面向流的协议,如果你要用它传输数据报(datagram),必然要自己实现stream2datagram的过程。这不叫解决问题,这叫实现功能。
- 第二个是tcp在实现的时候,为了解决大量小报文场景下包头比负载大,导致传输性价比太低的问题,专门设计的。其实在99%的情况下,Nagle算法根本就不会导致可感知的传输延迟,只是在某些场景下,Nagle算法和延迟ACK机制碰到一起,才会导致可感知的延迟。
1.2 粘包现象
定义server
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 |
public class ServerStarter { public static void main(String[] args) throws IOException { ServerSocket serverSocket = new ServerSocket(9999); Socket clientSocket = serverSocket.accept(); InputStream inputStream = clientSocket.getInputStream(); while (true) { byte[] bytes = new byte[30]; int count = inputStream.read(bytes); if (count > 0) { System.out.println("recv client msg:" + new String(bytes) ); } } } } |
定义client
|
1 2 3 4 5 6 7 8 9 10 |
public class ClientStarter { public static void main(String[] args) throws IOException { Socket client = new Socket("127.0.0.1", 9999); final String message = "Hello World"; OutputStream outputStream = client.getOutputStream(); for (int i = 0; i < 3; i++) { outputStream.write(message.getBytes()); } } } |
执行结果:发送3次,接受2次
|
1 2 |
recv client msg:Hello World recv client msg:Hello WorldHello World |
2 粘包原因
send和recv操作的是内核socket缓存区数据,内核TCP协议栈模块把socket缓存区的数据加上TCP/IP报文头,通过网卡发送客户端,所以在执行多次send操作,只是保存数据到socket缓存区,最终发送数据跟TCP协议有关:流控、拥塞控制、MSS大小。
在send数据时,也不需要考虑TCP包大小的限制,因为send只是把数据拷贝到内核socket缓存区,在内核网络协议栈模块才把内核sokcet缓存数据进行封装TCP流,需要考虑一个TCP 数据包的大下。
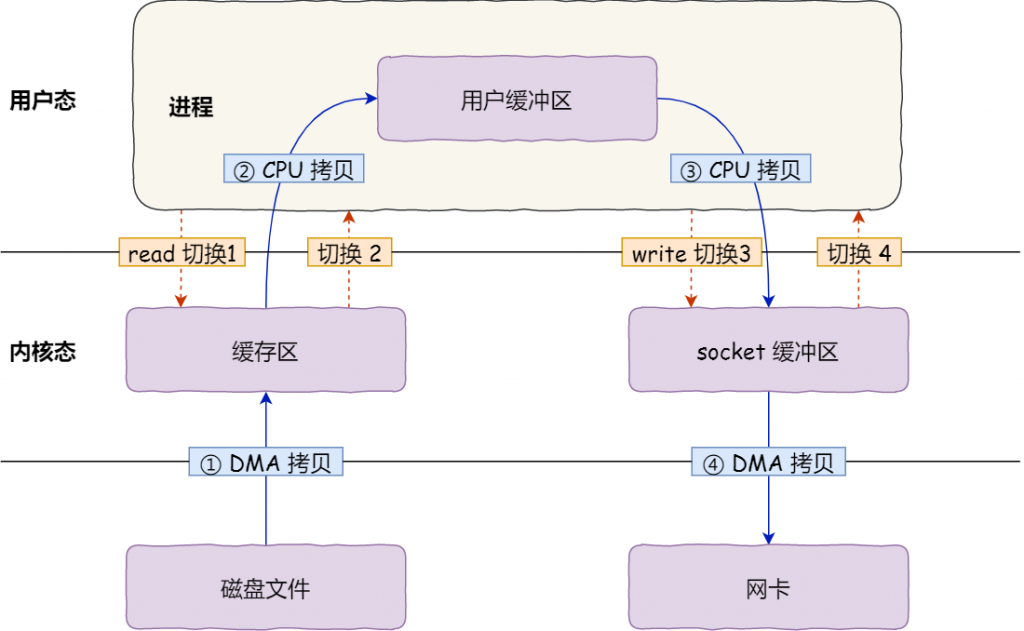
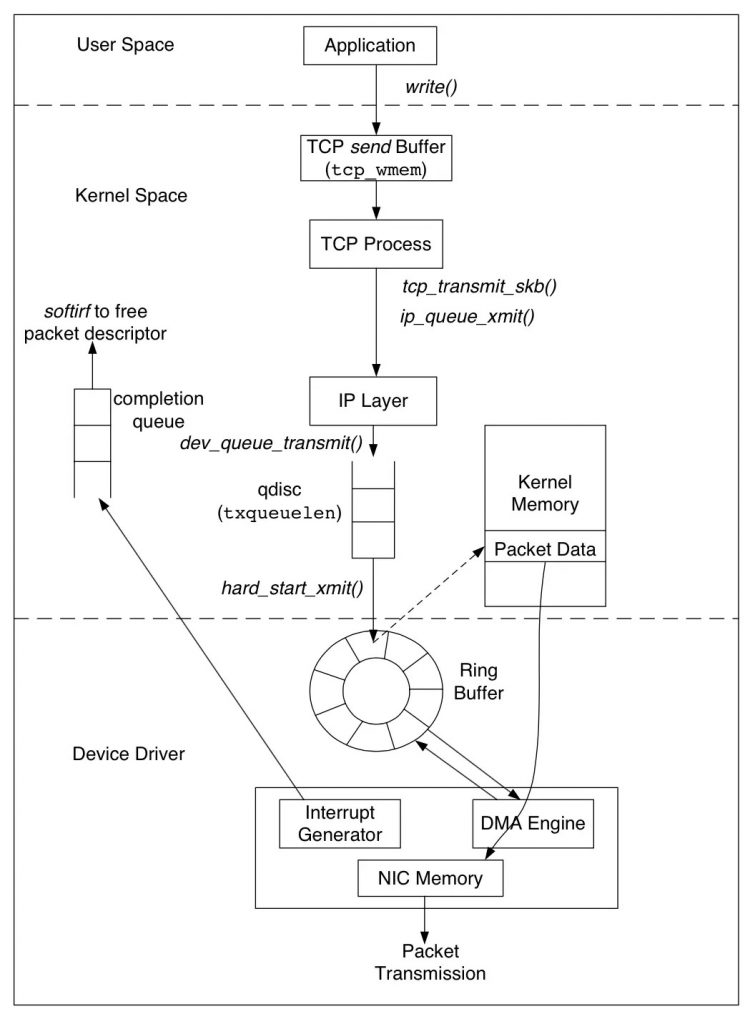
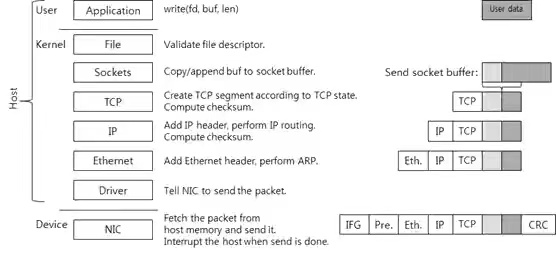
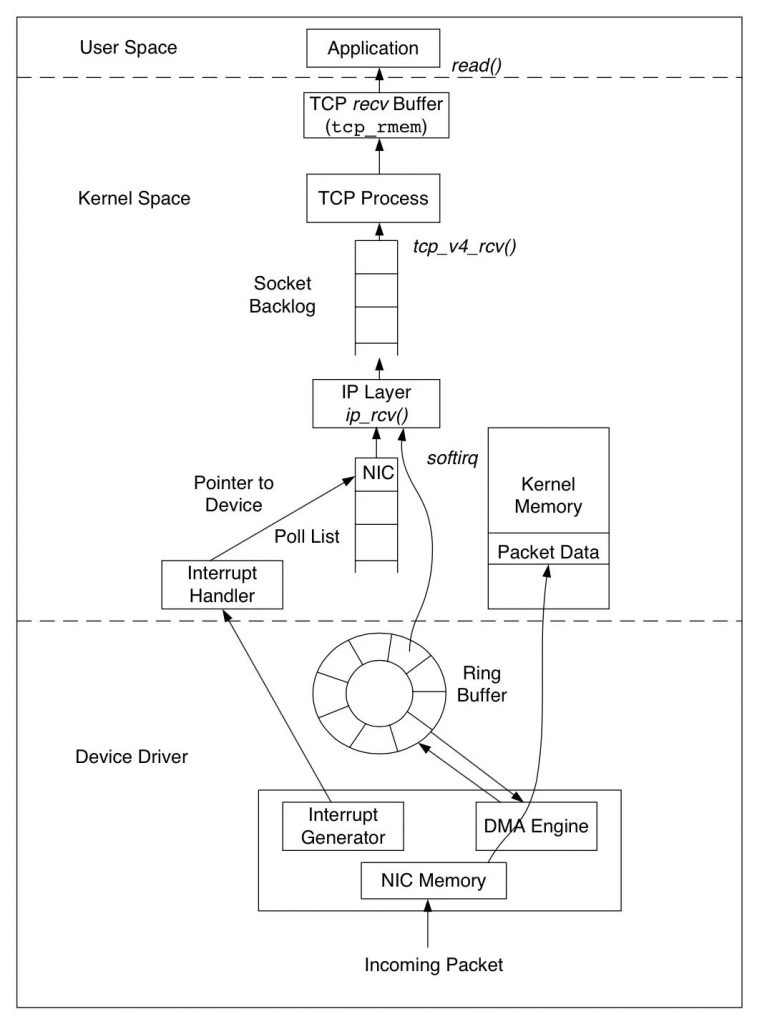
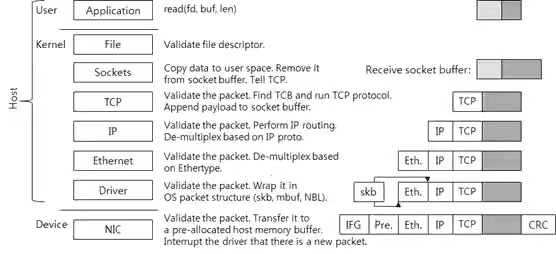
3 如何设计应用层协议的流到报文的编/解码
设计应用层协议常用方法:固定长度header (包含数据长度和编码等信息)+ body
3.1 HTTP
引用:https://www.zhihu.com/question/24598268
 应该说这是一个很简单很常见的问题,也不太想纠结“粘包”这个术语是否正确,如果将其定义为“HTTP解析器一次读socket操作获得的数据可能并不直接对应一个HTTP message”,那么应该说这个问题是必然会存在的。在面向stream的协议基础上实现一个面向message的协议,那么一般来说应用层和底层之间必然存在一个缓冲区和定时器。于是解析的过程就是,从socket中读取一次数据放入缓冲区,并检查目前buffer中内容是否是一个完整的message,如果是,提交给上层并修改队列起始位置,如果不是,不提交数据给上层。
应该说这是一个很简单很常见的问题,也不太想纠结“粘包”这个术语是否正确,如果将其定义为“HTTP解析器一次读socket操作获得的数据可能并不直接对应一个HTTP message”,那么应该说这个问题是必然会存在的。在面向stream的协议基础上实现一个面向message的协议,那么一般来说应用层和底层之间必然存在一个缓冲区和定时器。于是解析的过程就是,从socket中读取一次数据放入缓冲区,并检查目前buffer中内容是否是一个完整的message,如果是,提交给上层并修改队列起始位置,如果不是,不提交数据给上层。
- 一个是缓冲区必然要设定一个最大上限。
- 另一方面是一般要设置定时器,一段时间内某个连接没有传输足够数据就断开连接并清除buffer,否则很容易被恶意请求占用过多内存而影响整体稳定性
3.2 Netty
LenghtFieldBasedFrameDecode:适用于消息头包含消息长度的协议。
(翻译)")




