本文概览:总结一些kafka常见的问题
1 消费消息的阻塞模式
1.1 问题描述
问题复现:
STEP1:通过poll获取一批消息M1、M2…M5,假设成功处理了M1和M2,M3失败了。
STEP2: 第二次执行poll时,就是M6/M7了。
1.2 问题分析和解决
对于某些业务,上面错误是不准许的,如收益结算业务。必须保证第二次执行poll操作时,从M3开始,即M3、M4。
此时需要借助seek操作来完成,每次拉取都是从上次失败位置开始拉取消息
2 一个消费者监听多个topic
2.1 问题描述
消费者已经通过seek操作实现了阻塞属性,但是发现topic一直有lag。正常情况下如果存在lag大于0,在阻塞模式下,会一直拉取消息的,查看消费日志没有出现错误日志,给人第一感觉像是消费者线程卡死了。
2.2 问题分析
通过将日志级别设置为false,查看消费者日志,发现消费者一直在运行,只是拉取消息的起始位置是579,但是kafka服务器记录的logsize为579,offset=565,Lag=14,所以此时无法拉取565之后的数据。
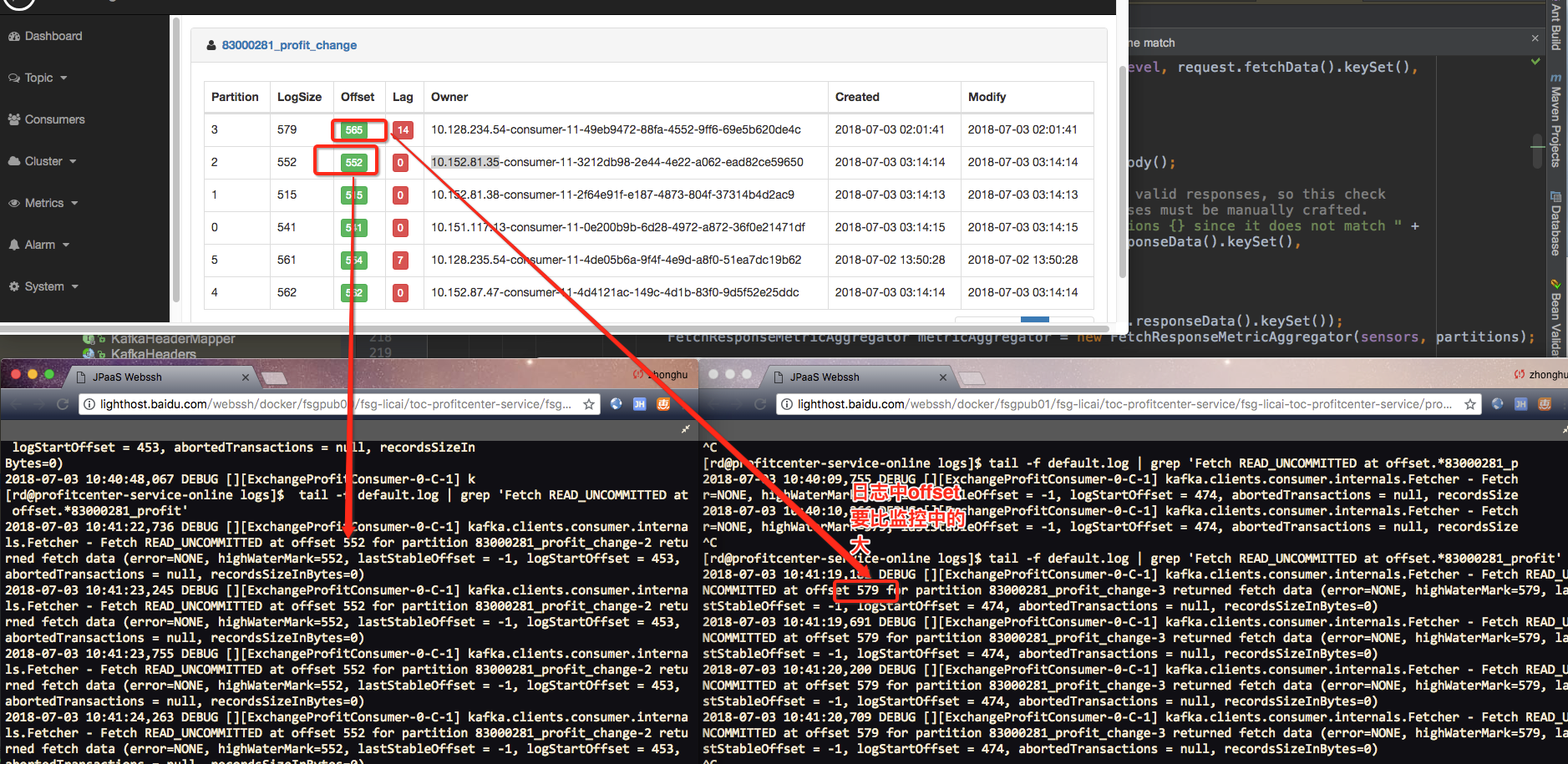
通过上面日志看到,消费者线程没有卡死,还在运行,只是拉取位置不正确,可能有两种原因:
- commit没有成功。此时会造成本地位置和服务器的offset位置不同
- seek没有起作用
再次确认消费者消费消息逻辑:
|
1 2 3 4 5 6 7 8 |
try{ step1 通过poll拉取消息 step2 线程池处理的业务消息,通过Callable的方式。 step3 通过future#get操作查看消息是否正常处理 step4 commit偏移量 } catche(Exception){ step5 seek当前有位置的消息。 } |
发现在消费者监听多个topic情况下,假设一次处理:T1-M4、T1-M5、T2-M4、T2-M5、T2-M6、T1-M6。当处理到T2-M5失败了,此时不会commit上面执行过的消息,并且此时会执行seek操作,但是seek只是操作了topic2,没有操作T1。此时重新拉取消息时,就会有问题:T2继续从T2-M5继续拉取,但是对于topic1,是从T1-M6位置开始拉取了,正常情况下对于topic1,应该是从T1-M5位置开始的。
这样可能出现多次,造成T1一直没有执行commit,但是又没有执行seek,直到T1-Mn是最后一条消息,此时就出现了上面日志中问题。
2.2 问题解决
在拉取到消息之后,首先对消息按照topic-partion分组。然后对每一个分组一次进行上面的处理:
|
1 2 3 4 5 6 7 8 |
try{ step1 通过poll拉取消息 step2 线程池处理的业务消息,通过Callable的方式。 step3 通过future#get操作查看消息是否正常处理 step4 commit偏移量 } catche(Exception){ step5 seek当前有位置的消息。 } |
3 一直重复拉取消息
1、问题描述
先看一段代码
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
try{ // 循环通过线程池处理消息 for (ConsumerRecord<String, Msg> data : datas) { logger.debug("receive data:" + data); Future<Integer> future = exec.submit(new MessageWorker(data, workerSwitchOn)); futureList.add(future); } // 依次get for (int i = 0; i < futureList.size(); i++) { futureList.get(i).get(executeTimeout, TimeUnit.MILLISECONDS); } } catche(Exception){ // 获取有问题消息的位置 ....getPostion... // 执行seek到改位置,这样可以重新拉取消息 ...seek... } |
这样会出现如下问题:
假设拉取100条消息,在第10条失败,抛异常,此时线程池阻塞队列中可能还是有90个线程,此时又重新拉取100条消息,假设此时第一条消息从超时异常,那么此时会再拉取100条消息,如此反复,阻塞队列中会有大量待处理的消息。
2、解决问题
对于
|
1 2 3 4 |
// 依次get for (int i = 0; i < futureList.size(); i++) { futureList.get(i).get(executeTimeout, TimeUnit.MILLISECONDS); } |
修改为如下,这样可以保证当前阻塞队列中线程都处理完成只有,再去拉取新的消息。
|
1 2 3 4 5 6 7 8 9 10 11 12 |
boolean isSumcess = true; for (int i = 0; i < futureList.size(); i++) { try { futureList.get(i).get(executeTimeout, TimeUnit.MILLISECONDS); } catch (ExecutionException te) { logger.error("execute consume work error ", te); isSuccess = false; } } if (!isSuccess) { throw new RuntimeException("execute error in this batch"); } |
4 监控
1、常常用到监控指标
logSize
lag
offset
注意:只有当一个topic被消费者群组监听之后,才有lag、offset的概念。一个topic-partion对应多个consumer-group,就对应多个lag和offset。

(翻译)")



